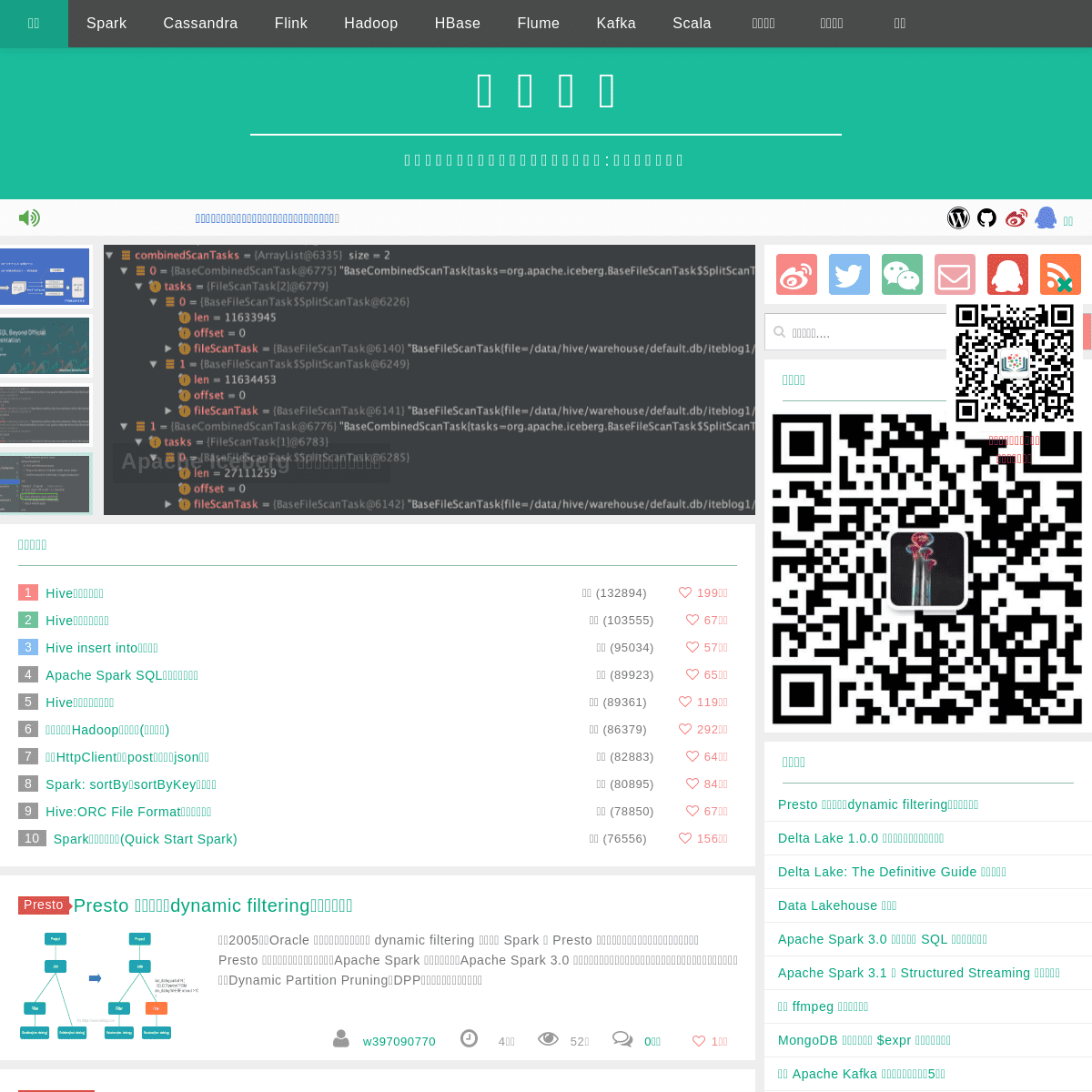
4
More Annotations



5




4
Favourite Annotations



2





2
Text
ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME ŤĶ∂Śú® Data + AI Summit 2021 šĻčŚČćÔľĆDelta Lake 1.0.0 ťáćÁ£ÖŚŹĎŚłÉԾƍŅôšł™ÁČąśú¨śėĮŚüļšļé Spark 3.1 ÁöĄÔľĆŚł¶śĚ•šļÜŤģłŚ§öśĖįÁČĻśÄß„Äāśú¨śĖáŚįÜÁĽďŚźą Michael Armbrust Ś§ßÁČõŚú® Data + AI Summit 2021 ÁöĄśľĒŤģ≤„ÄäAnnouncing Delta Lake 1.0„ÄčśĚ•šĽčÁĽć Delta Lake 1.0.0 ÁČąśú¨ÁöĄšłÄšļõťá捶ĀÁöĄśĖįÁČĻśÄß„Äā DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for Fashion
UI ELEMENTS
Common UI Features & Elements. Anim pariatur cliche reprehenderit, enim eiusmod high life accusamus terry richardson ad squid. 3 wolf moon officia aute, non cupidatat skateboard dolor brunch. APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: AMAZON WEB SERVICES ‚Ķ This registers S3AFileSystem as the default FileSystem for URIs with the s3:// scheme.. NativeS3FileSystem. This file system is limited to files up to 5GB in size and it does not work IAM roles (see Configure Access Credential), meaning that you have to manually configure your AWS credentials in the Hadoop config file.. You need to point Flink to a valid Hadoop configuration, which contains ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄ ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄÔľö śõīśĖįśó∂ťóīÔľö2015ŚĻī4śúą11śó• 11:05:06 ŚļŹŚŹ∑ ŚúįŚĚÄ ÁęĮŚŹ£ ŚõĹŚģ∂ ÁĪĽŚěč(ŚĆŅŚźćŚļ¶) Áä∂śÄĀ ŚÖ®śĶč 1 152.26.69.36 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 2 152.26.69.37 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 3 152.26.69.35 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤śĶčŤĮē 4
ŤŅáŚĺÄŤģįŚŅÜ
ŤŅáŚĺÄŤģįŚŅÜ
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: QUICKSTART Quickstart; Quickstart. Setup: Download and Start Flink. Download and Compile; Start a Local Flink Cluster; Read the Code; Run the Example; Next Steps; Get a Flink example program up and running in a few simplesteps.
APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: FLINKMLťÄöŤŅáśĖĻś≥ē
chainTransformerŚŹĮšĽ•ŚįÜšłÄšł™TransformerŚíĆŚŹ¶šłÄšł™śąĖŚ§öšł™Transformerťďĺśé•Śú®šłÄŤĶ∑„ÄāŤÄĆťÄöŤŅáśĖĻś≥ē chainPredictorŚŹĮšĽ•ŚįÜšłÄšł™ Predictor ŚíĆšłÄšł™śąĖŚ§öšł™Transformerťďĺśé•Śú®šłÄŤĶ∑„Äā. Ś¶āšĹēŤī°ÁĆģ. FlinkÁ§ĺŚĆļś¨ĘŤŅéśČÄśúČśúČŚŅ󜏟ťęėFlinkŚŹäŚÖ∂ÁõłŚÖ≥ŚļďÁöĄŤī°ÁĆģŤÄÖ„ÄāšłļšļÜśĖĻšĺŅŚŅęťÄüšļÜŤß£Ťī°ÁĆģÁöĄśĖĻś≥ēԾƍĮ∑ŚŹāÁú蜹ϚĽ¨ÁöĄŚģėśĖĻŤī°ÁĆģśĆáŚćó. APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ śú¨śĖáÁĹĎÁęôšłļApache CarbondataśúÄśĖįÁČąšł≠śĖáśĖáś°£ÔľĆÁĒĪŤŅáŚĺÄŤģįŚŅÜŚćöŚģĘÁŅĽŤĮĎ„Äā ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME ŤĶ∂Śú® Data + AI Summit 2021 šĻčŚČćÔľĆDelta Lake 1.0.0 ťáćÁ£ÖŚŹĎŚłÉԾƍŅôšł™ÁČąśú¨śėĮŚüļšļé Spark 3.1 ÁöĄÔľĆŚł¶śĚ•šļÜŤģłŚ§öśĖįÁČĻśÄß„Äāśú¨śĖáŚįÜÁĽďŚźą Michael Armbrust Ś§ßÁČõŚú® Data + AI Summit 2021 ÁöĄśľĒŤģ≤„ÄäAnnouncing Delta Lake 1.0„ÄčśĚ•šĽčÁĽć Delta Lake 1.0.0 ÁČąśú¨ÁöĄšłÄšļõťá捶ĀÁöĄśĖįÁČĻśÄß„Äā DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for FashionUI ELEMENTS
Common UI Features & Elements. Anim pariatur cliche reprehenderit, enim eiusmod high life accusamus terry richardson ad squid. 3 wolf moon officia aute, non cupidatat skateboard dolor brunch. APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: AMAZON WEB SERVICES ‚Ķ This registers S3AFileSystem as the default FileSystem for URIs with the s3:// scheme.. NativeS3FileSystem. This file system is limited to files up to 5GB in size and it does not work IAM roles (see Configure Access Credential), meaning that you have to manually configure your AWS credentials in the Hadoop config file.. You need to point Flink to a valid Hadoop configuration, which contains ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄ ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄÔľö śõīśĖįśó∂ťóīÔľö2015ŚĻī4śúą11śó• 11:05:06 ŚļŹŚŹ∑ ŚúįŚĚÄ ÁęĮŚŹ£ ŚõĹŚģ∂ ÁĪĽŚěč(ŚĆŅŚźćŚļ¶) Áä∂śÄĀ ŚÖ®śĶč 1 152.26.69.36 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 2 152.26.69.37 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 3 152.26.69.35 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤śĶčŤĮē 4
ŤŅáŚĺÄŤģįŚŅÜ
ŤŅáŚĺÄŤģįŚŅÜ
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: QUICKSTART Quickstart; Quickstart. Setup: Download and Start Flink. Download and Compile; Start a Local Flink Cluster; Read the Code; Run the Example; Next Steps; Get a Flink example program up and running in a few simplesteps.
APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: FLINKMLťÄöŤŅáśĖĻś≥ē
chainTransformerŚŹĮšĽ•ŚįÜšłÄšł™TransformerŚíĆŚŹ¶šłÄšł™śąĖŚ§öšł™Transformerťďĺśé•Śú®šłÄŤĶ∑„ÄāŤÄĆťÄöŤŅáśĖĻś≥ē chainPredictorŚŹĮšĽ•ŚįÜšłÄšł™ Predictor ŚíĆšłÄšł™śąĖŚ§öšł™Transformerťďĺśé•Śú®šłÄŤĶ∑„Äā. Ś¶āšĹēŤī°ÁĆģ. FlinkÁ§ĺŚĆļś¨ĘŤŅéśČÄśúČśúČŚŅ󜏟ťęėFlinkŚŹäŚÖ∂ÁõłŚÖ≥ŚļďÁöĄŤī°ÁĆģŤÄÖ„ÄāšłļšļÜśĖĻšĺŅŚŅęťÄüšļÜŤß£Ťī°ÁĆģÁöĄśĖĻś≥ēԾƍĮ∑ŚŹāÁú蜹ϚĽ¨ÁöĄŚģėśĖĻŤī°ÁĆģśĆáŚćó. APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ śú¨śĖáÁĹĎÁęôšłļApache CarbondataśúÄśĖįÁČąšł≠śĖáśĖáś°£ÔľĆÁĒĪŤŅáŚĺÄŤģįŚŅÜŚćöŚģĘÁŅĽŤĮĎ„Äā BUILDING UNDERSTANDING OUT OF INCOMPLETE AND BIASED Product Analytics helps us understand how users navigate our products and engage with our features, all with the aim of building betterproducts
WWW.ITEBLOG.COM
www.iteblog.com
SPUTNIK: AIRBNB‚ÄôS APACHE SPARK Typical Spark job ds=2010-01-01 ds=2010-01-02 ds=2010-01-03 ds=2010-01-01 ds=2010-01-02 Spark ApplicationŤŅáŚĺÄŤģįŚŅÜ
ŤŅáŚĺÄŤģįŚŅÜ
ŤŅáŚĺÄŤģįŚŅÜ-PAGE 57 šĹŅÁĒ®MapReduceŤß£ŚÜ≥šĽĽšĹēťóģťĘėšĻčŚČćԾƜąĎšĽ¨ťúÄŤ¶ĀŤÄÉŤôĎŚ¶āšĹēŤģĺŤģ°„ÄāŚĻ∂šłćśėĮšĽĽšĹēśó∂ŚÄôťÉĹťúÄŤ¶ĀmapŚíĆreduce job„ÄāMapReduceŤģĺŤģ°ś®°ŚľŹ(MapReduce Design Pattern)śēīšł™MapReducešĹúšłöÁöĄťė∂śģĶšłĽŤ¶ĀŚŹĮšĽ•ŚąÜšłļšĽ•šłčŚõõÁßćÔľö 1„ÄĀInput-Map-Reduce-Output 2„ÄĀInput-Map-Output 3„ÄĀInput-MultipleMaps-Reduce-Output
4„ÄĀInput-Map-Combiner-Reduce-OutputšłčťĚĘśąĎŚįÜšłÄšłÄšĽčÁĽćŚď™Áßć ŤŅáŚĺÄŤģįŚŅÜ-PAGE 40 śú¨šĻ¶šļé2017-03ÁĒĪPackt PublishingŚáļÁȹԾƚĹúŤÄÖMuhammad Asif AbbasiԾƌ֮šĻ¶356ť°Ķ„ÄāťÄöŤŅáśú¨šĻ¶šĹ†ŚįÜŚ≠¶ŚąįšĽ•šłčÁü•ŤĮÜÔľöGet an overview of big data analytics and its importance for organizations and data professionalsDelve into Spark to see how it is different from existing processing platformsUnderstand the intricacies of various file formats, and how to process them with Apache Spark ŤŅáŚĺÄŤģįŚŅÜ-PAGE 38 śú¨šĻ¶šļé2017-08ÁĒĪPackt PublishingŚáļÁȹԾƚĹúŤÄÖAnkit Jain, ŚÖ®šĻ¶341ť°Ķ„ÄāťÄöŤŅáśú¨šĻ¶šĹ†ŚįÜŚ≠¶ŚąįšĽ•šłčÁü•ŤĮÜUnderstand the core concepts of Apache Storm and real-time processingFollow the steps to deploy multiple nodes of Storm ClusterCreate Trident topologies to support various message-processing semanticsMake your cluster sharing effective using Storm schedulingIntegrate Apache Storm ŤŅáŚĺÄŤģįŚŅÜ-PAGE 87 šłčťĚĘipÁĒĪšļéŚúįŚĆļšłćŚźĆŚŹĮŤÉĹśó†ś≥ēŤģŅťóģԾƍĮ∑Ś§öŤĮēŚá†šł™„ÄāŚõĹŚÜÖťęėŚĆŅšĽ£ÁźÜ ip port ŚĆŅŚźćŚļ¶ ÁĪĽŚěč šĹćÁĹģ ŚďćŚļĒťÄüŚļ¶ śúÄŚźéť™ĆŤĮĀśó∂ťóī 125.117.130.174 9000 ťęėŚĆŅŚźć http ŤŅáŚĺÄŤģįŚŅÜ-PAGE 58 Áü•ŚźćÁöĄŚ§ßśēįśćģśäÄśúĮśě∂śěĄšłéŚļĒÁĒ®ŚąÜšļęśäÄśúĮŚćöŚģĘԾƌąÜšļęŚĆ֜訚ĹÜšłćťôźšļé Hadoop„ÄĀSpark„ÄĀKafka„ÄĀHudi„ÄĀIceberg„ÄĀDelta Lake Á≠ČŚ§ßśēįśćģÁõłŚÖ≥ÁöĄśäÄśúĮ„Äā ŤŅáŚĺÄŤģįŚŅÜ-PAGE 83SPARK SUMMIT
2015šľöŤģģšļéÁĺéŚõĹśó∂ťóī2015ŚĻī06śúą15śó•Śąį2015ŚĻī06śúą17śó•Śú®San FranciscoÔľąśóßťáĎŚĪĪԾȍŅõŤ°ĆÔľĆÁõģŚČćPPTŚ∑≤ÁĽŹŚÖ®ťÉ®ŚÖ¨ŚłÉšļÜԾƚłćŤŅáŚĺąťĀóśÜĺÁöĄśėĮŤŅôšł™ÁĹĎÁęôŤĘęŚĘôšļÜԾƜó†ś≥ēÁõīśé•ŤģŅťóģԾƜú¨ŚćöŚģĘŚįÜŤŅôšļõPPTŚÖ®ťÉ®śēī ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for FashionUI ELEMENTS
UI Elements Common UI Features & Elements. UI Elements. Raw denim you probably haven't heard of them jean shorts Austin. Food truck fixie locavore, accusamus mcsweeney's marfa nulla single-origin coffee squid. Etsy mixtape wayfarers, ethical wes anderson tofu before they sold out mcsweeney's organic lomo retro fanny pack lo-fi farm-to-table APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: AMAZON WEB SERVICES ‚Ķ This registers S3AFileSystem as the default FileSystem for URIs with the s3:// scheme.. NativeS3FileSystem. This file system is limited to files up to 5GB in size and it does not work IAM roles (see Configure Access Credential), meaning that you have to manually configure your AWS credentials in the Hadoop config file.. You need to point Flink to a valid Hadoop configuration, which contains ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄ ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄÔľö śõīśĖįśó∂ťóīÔľö2015ŚĻī4śúą11śó• 11:05:06 ŚļŹŚŹ∑ ŚúįŚĚÄ ÁęĮŚŹ£ ŚõĹŚģ∂ ÁĪĽŚěč(ŚĆŅŚźćŚļ¶) Áä∂śÄĀ ŚÖ®śĶč 1 152.26.69.36 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 2 152.26.69.37 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 3 152.26.69.35 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤śĶčŤĮē 4
ŤŅáŚĺÄŤģįŚŅÜ
ŤŅáŚĺÄŤģįŚŅÜ
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: QUICKSTART Sample Project in Scala. Linking with Flink. IDE Setup. Scala REPL. ŚÖ≥ŤĀĒŚŹĮťÄČś®°ŚĚó. Running Flink on Windows. Building Flink from Source. Application Development. Basic API Concepts. APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: FLINKML Ś¶āśěúšĹ†śÉ≥Áõīśé•ŚģěŤ∑Ķ, šĹ†ŚŹĮťúÄŤ¶Ā ŚąõŚĽļšłÄšł™FlinkÁ®čŚļŹ . ÁĄ∂ŚźéŚźéԾƌú®šĹ†ť°ĻÁõģÁöĄ pom.xml šł≠Śä†ŚÖ•FlinkMLÁöĄšĺĚŤĶĖ„Äā. org.apache.flink flink-ml_2.10 1.3-SNAPSHOT . ťúÄŤ¶Āś≥®śĄŹÁöĄśėĮFlinkMLÁõģŚČćś≤°śúČÁľĖŤĮĎŤŅõšļĆŤŅõŚą∂śĖᚼ∂ÁČą„Äā.ÁāĻŚáĽ
APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ ŚįÜśēįśćģŚä†ŤĹĹŚąį CARBONDATA Ť°®šł≠. ŤŅôšł™ŚĎĹšĽ§ÁĒ®šļéŚä†ŤĹĹ csv ś†ľŚľŹÁöĄśĖᚼ∂Śąį carbondata Ť°®šł≠, OPTIONS ŚŹāśēįŚú®Śä†ŤĹĹśēįśćģÁöĄŤŅáÁ®čšł≠śėĮŚŹĮťÄČÁöĄ„Äā. Śú® OPTIONS šł≠śąĎšĽ¨ŚŹĮšĽ•śĆáŚģöšĽĽšĹēÁöĄŚÖąŚÜ≥śĚ°šĽ∂ԾƜĮĒŚ¶āÔľöDELIMITER, QUOTECHAR, FILEHEADER, ESCAPECHAR, MULTILINE„Äā. LOAD DATA INPATH 'folder_path' INTO ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for FashionUI ELEMENTS
UI Elements Common UI Features & Elements. UI Elements. Raw denim you probably haven't heard of them jean shorts Austin. Food truck fixie locavore, accusamus mcsweeney's marfa nulla single-origin coffee squid. Etsy mixtape wayfarers, ethical wes anderson tofu before they sold out mcsweeney's organic lomo retro fanny pack lo-fi farm-to-table APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: AMAZON WEB SERVICES ‚Ķ This registers S3AFileSystem as the default FileSystem for URIs with the s3:// scheme.. NativeS3FileSystem. This file system is limited to files up to 5GB in size and it does not work IAM roles (see Configure Access Credential), meaning that you have to manually configure your AWS credentials in the Hadoop config file.. You need to point Flink to a valid Hadoop configuration, which contains ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄ ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄÔľö śõīśĖįśó∂ťóīÔľö2015ŚĻī4śúą11śó• 11:05:06 ŚļŹŚŹ∑ ŚúįŚĚÄ ÁęĮŚŹ£ ŚõĹŚģ∂ ÁĪĽŚěč(ŚĆŅŚźćŚļ¶) Áä∂śÄĀ ŚÖ®śĶč 1 152.26.69.36 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 2 152.26.69.37 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 3 152.26.69.35 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤śĶčŤĮē 4
ŤŅáŚĺÄŤģįŚŅÜ
ŤŅáŚĺÄŤģįŚŅÜ
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: QUICKSTART Sample Project in Scala. Linking with Flink. IDE Setup. Scala REPL. ŚÖ≥ŤĀĒŚŹĮťÄČś®°ŚĚó. Running Flink on Windows. Building Flink from Source. Application Development. Basic API Concepts. APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: FLINKML Ś¶āśěúšĹ†śÉ≥Áõīśé•ŚģěŤ∑Ķ, šĹ†ŚŹĮťúÄŤ¶Ā ŚąõŚĽļšłÄšł™FlinkÁ®čŚļŹ . ÁĄ∂ŚźéŚźéԾƌú®šĹ†ť°ĻÁõģÁöĄ pom.xml šł≠Śä†ŚÖ•FlinkMLÁöĄšĺĚŤĶĖ„Äā. org.apache.flink flink-ml_2.10 1.3-SNAPSHOT . ťúÄŤ¶Āś≥®śĄŹÁöĄśėĮFlinkMLÁõģŚČćś≤°śúČÁľĖŤĮĎŤŅõšļĆŤŅõŚą∂śĖᚼ∂ÁČą„Äā.ÁāĻŚáĽ
APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ ŚįÜśēįśćģŚä†ŤĹĹŚąį CARBONDATA Ť°®šł≠. ŤŅôšł™ŚĎĹšĽ§ÁĒ®šļéŚä†ŤĹĹ csv ś†ľŚľŹÁöĄśĖᚼ∂Śąį carbondata Ť°®šł≠, OPTIONS ŚŹāśēįŚú®Śä†ŤĹĹśēįśćģÁöĄŤŅáÁ®čšł≠śėĮŚŹĮťÄČÁöĄ„Äā. Śú® OPTIONS šł≠śąĎšĽ¨ŚŹĮšĽ•śĆáŚģöšĽĽšĹēÁöĄŚÖąŚÜ≥śĚ°šĽ∂ԾƜĮĒŚ¶āÔľöDELIMITER, QUOTECHAR, FILEHEADER, ESCAPECHAR, MULTILINE„Äā. LOAD DATA INPATH 'folder_path' INTO BUILDING UNDERSTANDING OUT OF INCOMPLETE AND BIASED Product Analytics helps us understand how users navigate our products and engage with our features, all with the aim of building betterproducts
AUTOMATED & EXPLAINABLE DEEP Disclaimer Roche has been one of John Snow Labs’ customers since August 2018. This presentation has been prepared by Roche and John Snow Labs to provide a high-level over view of Roche’s use of John Snow Labs’ products. Nothing contained or stated herein or during the presentation constitutes Roche’s endorsement of John SnowLabs’ products.
SPUTNIK: AIRBNB‚ÄôS APACHE SPARK Typical Spark job ds=2010-01-01 ds=2010-01-02 ds=2010-01-03 ds=2010-01-01 ds=2010-01-02 Spark ApplicationŤŅáŚĺÄŤģįŚŅÜ
ŤŅáŚĺÄŤģįŚŅÜ
WWW.ITEBLOG.COM
www.iteblog.com
ŤŅáŚĺÄŤģįŚŅÜ-PAGE 40 śú¨šĻ¶šļé2017-03ÁĒĪPackt PublishingŚáļÁȹԾƚĹúŤÄÖMuhammad Asif AbbasiԾƌ֮šĻ¶356ť°Ķ„ÄāťÄöŤŅáśú¨šĻ¶šĹ†ŚįÜŚ≠¶ŚąįšĽ•šłčÁü•ŤĮÜÔľöGet an overview of big data analytics and its importance for organizations and data professionalsDelve into Spark to see how it is different from existing processing platformsUnderstand the intricacies of various file formats, and how to process them with Apache Spark ŤŅáŚĺÄŤģįŚŅÜ-PAGE 65 Áü•ŚźćÁöĄŚ§ßśēįśćģśäÄśúĮśě∂śěĄšłéŚļĒÁĒ®ŚąÜšļęśäÄśúĮŚćöŚģĘԾƌąÜšļęŚĆ֜訚ĹÜšłćťôźšļé Hadoop„ÄĀSpark„ÄĀKafka„ÄĀHudi„ÄĀIceberg„ÄĀDelta Lake Á≠ČŚ§ßśēįśćģÁõłŚÖ≥ÁöĄśäÄśúĮ„Äā ŤŅáŚĺÄŤģįŚŅÜ-PAGE 87 šłčťĚĘipÁĒĪšļéŚúįŚĆļšłćŚźĆŚŹĮŤÉĹśó†ś≥ēŤģŅťóģԾƍĮ∑Ś§öŤĮēŚá†šł™„ÄāŚõĹŚÜÖťęėŚĆŅšĽ£ÁźÜ ip port ŚĆŅŚźćŚļ¶ ÁĪĽŚěč šĹćÁĹģ ŚďćŚļĒťÄüŚļ¶ śúÄŚźéť™ĆŤĮĀśó∂ťóī 125.117.130.174 9000 ťęėŚĆŅŚźć http ŤŅáŚĺÄŤģįŚŅÜ-PAGE 64 Śú®Ść≥ŚįÜŚŹĎŚłÉÁöĄApache Spark 2.0šł≠ŚįÜšľöśŹźšĺõśúļŚô®Ś≠¶šĻ†ś®°ŚěčśĆĀšĻÖŚĆĖŤÉĹŚäõ„ÄāśúļŚô®Ś≠¶šĻ†ś®°ŚěčśĆĀšĻÖŚĆĖÔľąśúļŚô®Ś≠¶šĻ†ś®°ŚěčÁöĄšŅĚŚ≠ėŚíƌ䆍ĹĹԾȚĹŅŚĺ󚼕šłčšłČÁĪĽśúļŚô®Ś≠¶šĻ†ŚúļśôĮŚŹėŚĺóŚģĻśėďÔľö 1„ÄĀśēįśćģÁßĎŚ≠¶Śģ∂ŚľÄŚŹĎMLś®°ŚěčŚĻ∂Á߼šļ§ÁĽôŚ∑•Á®čŚłąŚõĘťėüŚú®ÁĒüšļßÁéĮŚĘÉšł≠ŚŹĎŚłÉÔľõ 2„ÄĀśēįśćģŚ∑•Á®čŚłąśä䚳Ěł™PythonŤĮ≠Ť®ÄŚľÄŚŹĎÁöĄśúļŚô®Ś≠¶šĻ†ś®°ŚěčŤģ≠ÁĽÉŚ∑•šĹúśĶĀťõÜśąźŚąįšłÄšł™Java ŤŅáŚĺÄŤģįŚŅÜ-PAGE 86 Ś¶āśěúšĹ†ÁöĄDriverŚÜÖŚ≠ėŚģĻťáŹšłćŤÉĹŚģĻÁļ≥šłÄšł™Ś§ßŚěčRDDťáĆťĚĘÁöĄśČÄśúČśēįśćģԾƝā£šĻąšłćŤ¶ĀŚĀöšĽ•šłčśďćšĹúÔľöval values = iteblogVeryLargeRDD.collect() Collect śďćšĹúšľöŤĮēŚõĺŚįÜ RDD ťáĆťĚĘÁöĄśĮŹšłÄśĚ°śēįśćģŚ§ćŚą∂ŚąįDriveršłäԾƌ¶āśěúšĹ†DriverÁęĮÁöĄŚÜÖŚ≠ėśó†ś≥ēŤ£ÖšłčŤŅôšļõśēįśćģԾƍŅôśó∂ŚÄôšľöŚŹĎÁĒüŚÜÖŚ≠ėśļĘŚáļŚíĆŚī©śļÉ„Äā ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for Fashion SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ Apache Spark 3.0 śėĮŚ¶āšĹēśŹźťęė SQL Ś∑•šĹúŤīüŤĹĹÁöĄśÄߍÉĹ. Śú®Śá†šĻéśČÄśúČŚ§ĄÁźÜŚ§ćśĚāśēįśćģÁöĄťĘÜŚüüÔľĆSpark Ś∑≤ÁĽŹŤŅÖťÄüśąźšłļśēįśćģŚíĆŚąÜśěźÁĒüŚĎĹŚĎ®śúüŚõĘťėüÁöĄšļčŚģěšłäÁöĄŚąÜŚłÉŚľŹŤģ°Áģóś°Üśě∂„Äā.Spark 3.0
śúÄŚŹóśúüŚĺÖÁöĄÁČĻśÄßšĻ蚳ĜėĮśĖįÁöĄŤá™ťÄāŚļĒśü•ŤĮĘśČߍ°Ćś°Üśě∂ (Adaptive Query ExecutionÔľĆAQE)ԾƍĮ•ś°Üśě∂Ťß£ŚÜ≥šļÜŤģłŚ§ö Spark SQL UBUNTU 10.04.4 LTSšłčŤĹĹŚúįŚĚÄ Ubuntu 10.04.4 LTSšłčŤĹĹŚúįŚĚÄ. ŚąÜšļę ( 0) śĖáÁę†ÁõģŚĹē 1 Select an image. 1.1 Desktop CD. 1.2 Server install CD. 1.3 Alternate install CD. This directory contains the most frequently downloaded Ubuntu images. Other images, including DVDs and source CDs, may be available on the cdimage server. ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄ ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄÔľö śõīśĖįśó∂ťóīÔľö2015ŚĻī4śúą11śó• 11:05:06 ŚļŹŚŹ∑ ŚúįŚĚÄ ÁęĮŚŹ£ ŚõĹŚģ∂ ÁĪĽŚěč(ŚĆŅŚźćŚļ¶) Áä∂śÄĀ ŚÖ®śĶč 1 152.26.69.36 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 2 152.26.69.37 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 3 152.26.69.35 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤śĶčŤĮē 4
APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
JAVAŤé∑ŚŹĖŚ∑•Á®čŤ∑ĮŚĺĄÁöĄŚá†ÁßćśĖĻś≥ē ‚Äď Á¨¨šļĒÁßćÔľö. System.out.println ( System.getProperty ("java.class.path")); ÁĽďśěúÔľö. C:\Documents and Settings\Administrator\workspace\projectName\bin. Ťé∑ŚŹĖŚĹďŚČćŚ∑•Á®čŤ∑ĮŚĺĄ. śú¨ŚćöŚģĘśĖáÁꆝô§ÁČĻŚąęŚ£įśėéԾƌ֮ťÉ®ťÉĹśėĮŚéüŚąõÔľĀ. ŚéüŚąõśĖáÁę†ÁČąśĚÉŚĹíŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģÔľą ŤŅáŚĺÄŤģįŚŅÜ ÔľČśČÄśúČԾƜú™ÁĽŹŤģłŚŹĮšłćŚĺóŤĹ¨ŤĹĹ„Äā. śú¨śĖá HBASE ŚćŹŚ§ĄÁźÜŚô®ŚÖ•ťó®ŚŹäŚģěśąė HBase ŚíĆ MapReduce śúČŚĺąťęėÁöĄťõÜśąźÔľĆśąĎšĽ¨ŚŹĮšĽ•šĹŅÁĒ® MRŚĮĻŚ≠ėŚā®Śú® HBase
šł≠ÁöĄśēįśćģŤŅõŤ°ĆŚąÜŚłÉŚľŹŤģ°Áģó„ÄāšĹÜśėĮŚú®ŚĺąŚ§öśÉÖŚÜĶšłčԾƚĺ茶āÁģÄŚćēÁöĄŚä†ś≥ēŤģ°ÁģóśąĖŤÄÖŤĀöŚźąśďćšĹúÔľąśĪāŚíĆ„ÄĀŤģ°śēįÁ≠ČÔľČԾƌ¶āśěúŤÉĹŚ§üŚįÜŤŅôšļõŤģ°Áģóśé®ťÄĀŚąį RegionServerԾƍŅôŚįÜŚ§ßŚ§ßŚáŹŚįĎśúćŚä°Śô®ŚíĆŚģĘśą∑ÁöĄÁöĄśēįśćģťÄöšŅ°ŚľÄťĒÄԾƚĽéŤÄĆśŹźťęė HBase ÁöĄŤģ°ÁģóśÄߍÉĹԾƍŅôŚįĪśėĮśú¨śĖ፶ĀšĽčÁĽćÁöĄ Śú® DOCKER šł≠ŤŅźŤ°Ć APACHE PHOENIX ŚĻ∂ŚźĮÁĒ®ŤŅúÁ®čŤįÉŤĮē śúÄŤŅĎÁĒĪšļéŚ∑•šĹúśĖĻťĚĘÁöĄŚéüŚõ†ťúÄŤ¶ĀŤß£śěź Apache Phoenix ŚļēŚĪāÁöĄŚéüŚßčśĖᚼ∂ԾƚĻüŚįĪśėĮŚ≠ėŚú® HDFS šłäÁöĄ HFile„ÄāšĹÜśėĮÁĒĪšļé Phoenix śúȍᙍļęÁöĄšłÄŚ•óśēįśćģÁľĖÁ†ĀśĖĻŚľŹÔľĆšĹÜśėĮÁĒĪšļéśú¨šļļŚĮĻ Phoenix ŤŅôŚ•óś†Ļśú¨ŚįĪšłćÁÜüśāČԾƜČÄšĽ•ŚŹ™ŤÉōᙌ∑ĪŚéĽÁúčÁõłŚÖ≥šĽ£Á†Ā„ÄāšĹÜśėĮApache Phoenix
śėĮšł™Ś§ßŚ∑•Á®čŚēäԾƚłćŚŹĮŤÉĹšłÄšł™šłÄšł™śĖᚼ∂ŚéĽśČĺÁöĄÔľĆŤŅôšľöÁõłŚĹďÁöĄśÖĘ„Äā Ść≥ŚįÜŚŹĎŚłÉÁöĄ APACHE KAFKA 2.8 ŚįÜšłćťúÄŤ¶ĀšĺĚŤĶĖ ‚ĶTRANSLATE THISPAGE
Apache Kafka ÁöĄś†łŚŅÉŤģĺŤģ°śėĮśó•ŚŅóÔľąLogԾȂÄĒ‚ÄĒ šłÄšł™ÁģÄŚćēÁöĄśēįśćģÁĽďśěĄÔľĆšĹŅÁĒ®ť°ļŚļŹśďćšĹú„ÄāšĽ•śó•ŚŅóšłļšł≠ŚŅÉÁöĄŤģĺŤģ°Śł¶śĚ•šļÜťęėśēąÁöĄÁ£ĀÁõėÁľďŚÜ≤ŚíĆCPU
ÁľďŚ≠ėšĹŅÁĒ®„ÄĀťĘĄŚŹĖ„ÄĀťõ∂śč∑ŤīĚśēįśćģšľ†ŤĺďŚíĆŤģłŚ§öŚÖ∂šĽĖŚ•ĹŚ§ĄÔľĆšĽéŤÄĆšĹŅKafka
ŤÉĹŚ§üśŹźšĺõťęėśēąÁéáŚíĆŚźěŚźźťáŹÁöĄŚäüŤÉĹ„ÄāŚĮĻšļéťā£šļõŚąöśé•Ťß¶ Kafka ÁöĄšļļśĚ•ŤĮīԾƚłĽťĘėÔľątopicԾȚĽ•ŚŹäśŹźšļ§śó•ŚŅóÁöĄ ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for Fashion SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ Apache Spark 3.0 śėĮŚ¶āšĹēśŹźťęė SQL Ś∑•šĹúŤīüŤĹĹÁöĄśÄߍÉĹ. Śú®Śá†šĻéśČÄśúČŚ§ĄÁźÜŚ§ćśĚāśēįśćģÁöĄťĘÜŚüüÔľĆSpark Ś∑≤ÁĽŹŤŅÖťÄüśąźšłļśēįśćģŚíĆŚąÜśěźÁĒüŚĎĹŚĎ®śúüŚõĘťėüÁöĄšļčŚģěšłäÁöĄŚąÜŚłÉŚľŹŤģ°Áģóś°Üśě∂„Äā.Spark 3.0
śúÄŚŹóśúüŚĺÖÁöĄÁČĻśÄßšĻ蚳ĜėĮśĖįÁöĄŤá™ťÄāŚļĒśü•ŤĮĘśČߍ°Ćś°Üśě∂ (Adaptive Query ExecutionÔľĆAQE)ԾƍĮ•ś°Üśě∂Ťß£ŚÜ≥šļÜŤģłŚ§ö Spark SQL UBUNTU 10.04.4 LTSšłčŤĹĹŚúįŚĚÄ Ubuntu 10.04.4 LTSšłčŤĹĹŚúįŚĚÄ. ŚąÜšļę ( 0) śĖáÁę†ÁõģŚĹē 1 Select an image. 1.1 Desktop CD. 1.2 Server install CD. 1.3 Alternate install CD. This directory contains the most frequently downloaded Ubuntu images. Other images, including DVDs and source CDs, may be available on the cdimage server. ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄ ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄÔľö śõīśĖįśó∂ťóīÔľö2015ŚĻī4śúą11śó• 11:05:06 ŚļŹŚŹ∑ ŚúįŚĚÄ ÁęĮŚŹ£ ŚõĹŚģ∂ ÁĪĽŚěč(ŚĆŅŚźćŚļ¶) Áä∂śÄĀ ŚÖ®śĶč 1 152.26.69.36 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 2 152.26.69.37 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 3 152.26.69.35 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤śĶčŤĮē 4
APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
JAVAŤé∑ŚŹĖŚ∑•Á®čŤ∑ĮŚĺĄÁöĄŚá†ÁßćśĖĻś≥ē ‚Äď Á¨¨šļĒÁßćÔľö. System.out.println ( System.getProperty ("java.class.path")); ÁĽďśěúÔľö. C:\Documents and Settings\Administrator\workspace\projectName\bin. Ťé∑ŚŹĖŚĹďŚČćŚ∑•Á®čŤ∑ĮŚĺĄ. śú¨ŚćöŚģĘśĖáÁꆝô§ÁČĻŚąęŚ£įśėéԾƌ֮ťÉ®ťÉĹśėĮŚéüŚąõÔľĀ. ŚéüŚąõśĖáÁę†ÁČąśĚÉŚĹíŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģÔľą ŤŅáŚĺÄŤģįŚŅÜ ÔľČśČÄśúČԾƜú™ÁĽŹŤģłŚŹĮšłćŚĺóŤĹ¨ŤĹĹ„Äā. śú¨śĖá HBASE ŚćŹŚ§ĄÁźÜŚô®ŚÖ•ťó®ŚŹäŚģěśąė HBase ŚíĆ MapReduce śúČŚĺąťęėÁöĄťõÜśąźÔľĆśąĎšĽ¨ŚŹĮšĽ•šĹŅÁĒ® MRŚĮĻŚ≠ėŚā®Śú® HBase
šł≠ÁöĄśēįśćģŤŅõŤ°ĆŚąÜŚłÉŚľŹŤģ°Áģó„ÄāšĹÜśėĮŚú®ŚĺąŚ§öśÉÖŚÜĶšłčԾƚĺ茶āÁģÄŚćēÁöĄŚä†ś≥ēŤģ°ÁģóśąĖŤÄÖŤĀöŚźąśďćšĹúÔľąśĪāŚíĆ„ÄĀŤģ°śēįÁ≠ČÔľČԾƌ¶āśěúŤÉĹŚ§üŚįÜŤŅôšļõŤģ°Áģóśé®ťÄĀŚąį RegionServerԾƍŅôŚįÜŚ§ßŚ§ßŚáŹŚįĎśúćŚä°Śô®ŚíĆŚģĘśą∑ÁöĄÁöĄśēįśćģťÄöšŅ°ŚľÄťĒÄԾƚĽéŤÄĆśŹźťęė HBase ÁöĄŤģ°ÁģóśÄߍÉĹԾƍŅôŚįĪśėĮśú¨śĖ፶ĀšĽčÁĽćÁöĄ Śú® DOCKER šł≠ŤŅźŤ°Ć APACHE PHOENIX ŚĻ∂ŚźĮÁĒ®ŤŅúÁ®čŤįÉŤĮē śúÄŤŅĎÁĒĪšļéŚ∑•šĹúśĖĻťĚĘÁöĄŚéüŚõ†ťúÄŤ¶ĀŤß£śěź Apache Phoenix ŚļēŚĪāÁöĄŚéüŚßčśĖᚼ∂ԾƚĻüŚįĪśėĮŚ≠ėŚú® HDFS šłäÁöĄ HFile„ÄāšĹÜśėĮÁĒĪšļé Phoenix śúȍᙍļęÁöĄšłÄŚ•óśēįśćģÁľĖÁ†ĀśĖĻŚľŹÔľĆšĹÜśėĮÁĒĪšļéśú¨šļļŚĮĻ Phoenix ŤŅôŚ•óś†Ļśú¨ŚįĪšłćÁÜüśāČԾƜČÄšĽ•ŚŹ™ŤÉōᙌ∑ĪŚéĽÁúčÁõłŚÖ≥šĽ£Á†Ā„ÄāšĹÜśėĮApache Phoenix
śėĮšł™Ś§ßŚ∑•Á®čŚēäԾƚłćŚŹĮŤÉĹšłÄšł™šłÄšł™śĖᚼ∂ŚéĽśČĺÁöĄÔľĆŤŅôšľöÁõłŚĹďÁöĄśÖĘ„Äā Ść≥ŚįÜŚŹĎŚłÉÁöĄ APACHE KAFKA 2.8 ŚįÜšłćťúÄŤ¶ĀšĺĚŤĶĖ ‚ĶTRANSLATE THISPAGE
Apache Kafka ÁöĄś†łŚŅÉŤģĺŤģ°śėĮśó•ŚŅóÔľąLogԾȂÄĒ‚ÄĒ šłÄšł™ÁģÄŚćēÁöĄśēįśćģÁĽďśěĄÔľĆšĹŅÁĒ®ť°ļŚļŹśďćšĹú„ÄāšĽ•śó•ŚŅóšłļšł≠ŚŅÉÁöĄŤģĺŤģ°Śł¶śĚ•šļÜťęėśēąÁöĄÁ£ĀÁõėÁľďŚÜ≤ŚíĆCPU
ÁľďŚ≠ėšĹŅÁĒ®„ÄĀťĘĄŚŹĖ„ÄĀťõ∂śč∑ŤīĚśēįśćģšľ†ŤĺďŚíĆŤģłŚ§öŚÖ∂šĽĖŚ•ĹŚ§ĄÔľĆšĽéŤÄĆšĹŅKafka
ŤÉĹŚ§üśŹźšĺõťęėśēąÁéáŚíĆŚźěŚźźťáŹÁöĄŚäüŤÉĹ„ÄāŚĮĻšļéťā£šļõŚąöśé•Ťß¶ Kafka ÁöĄšļļśĚ•ŤĮīԾƚłĽťĘėÔľątopicԾȚĽ•ŚŹäśŹźšļ§śó•ŚŅóÁöĄ SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ ŤĶ∂Śú® Data + AI Summit 2021 šĻčŚČćÔľĆDelta Lake 1.0.0 ťáćÁ£ÖŚŹĎŚłÉԾƍŅôšł™ÁČąśú¨śėĮŚüļšļé Spark 3.1 ÁöĄÔľĆŚł¶śĚ•šļÜŤģłŚ§öśĖįÁČĻśÄß„Äāśú¨śĖáŚįÜÁĽďŚźą Michael Armbrust Ś§ßÁČõŚú® Data + AI Summit 2021 ÁöĄśľĒŤģ≤„ÄäAnnouncing Delta Lake 1.0„ÄčśĚ•šĽčÁĽć Delta Lake 1.0.0 ÁČąśú¨ÁöĄšłÄšļõťá捶ĀÁöĄśĖįÁČĻśÄß„Äā šļĒśúą ‚Äď 2021 ‚Äď ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGE ŤĶ∂Śú® Data + AI Summit 2021 šĻčŚČćÔľĆDelta Lake 1.0.0 ťáćÁ£ÖŚŹĎŚłÉԾƍŅôšł™ÁČąśú¨śėĮŚüļšļé Spark 3.1 ÁöĄÔľĆŚł¶śĚ•šļÜŤģłŚ§öśĖįÁČĻśÄß„Äāśú¨śĖáŚįÜÁĽďŚźą Michael Armbrust Ś§ßÁČõŚú® Data + AI Summit 2021 ÁöĄśľĒŤģ≤„ÄäAnnouncing Delta Lake 1.0„ÄčśĚ•šĽčÁĽć Delta Lake 1.0.0 ÁČąśú¨ÁöĄšłÄšļõťá捶ĀÁöĄśĖįÁČĻśÄß„Äā DASHBOARD - ACE ADMIN(BOOTSTRAPŚźéŚŹįÁģ°ÁźÜÁ≥ĽÁĽüś®°ÁČąACEšłčŤĹĹ) Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque commodo massa sed ipsum porttitor facilisis. HBASE ‚Äď ŤŅáŚĺÄŤģįŚŅÜ-PAGE 3TRANSLATE THIS PAGE ŤÉĆśôĮťöŹÁĚÄ Apache HBase Śú®ŚźĄšł™ťĘÜŚüüÁöĄŚĻŅś≥õŚļĒÁĒ®ÔľĆŚú® HBase ŤŅźÁĽīśąĖŚļĒÁĒ®ÁöĄŤŅáÁ®čšł≠śąĎšĽ¨ŚŹĮŤÉĹšľöťĀጹįŤŅôś†∑ÁöĄťóģťĘėÔľöŚźĆšłÄšł™HBase
ťõÜÁ姚ĹŅÁĒ®ÁöĄÁĒ®śą∑Ť∂äśĚ•Ť∂䌧öԾƚłćŚźĆÁĒ®śą∑šĻčťóīÁöĄŤĮĽŚÜôśąĖŤÄÖšłćŚźĆŤ°®ÁöĄ compaction„ÄĀregion splits śďćšĹúŚŹĮŤÉĹŚĮĻŚÖ∂šĽĖÁĒ®śą∑śąĖŤ°®šļßÁĒüšļÜŚĹĪŚďć„Äā APACHE HUDI CLUSTERING śēįśćģŚłÉŚĪÄŚäüŤÉĹšĽčÁĽć šłļŤÉĹŚ§üśĒĮśĆĀŚŅęťÄüśĎĄŚŹĖÁöĄŚźĆśó∂šłćŚĹĪŚďćśü•ŤĮĘśÄߍÉĹԾƜąĎšĽ¨ŚľēŚÖ•šļÜClusteringśúćŚä°śĚ•ťáćŚÜôśēįśćģšĽ•šľėŚĆĖHudiśēįśćģśĻĖśĖᚼ∂ÁöĄŚłÉŚĪÄ„Äā. ClusteringśúćŚä°ŚŹĮšĽ•Śľāś≠•śąĖŚźĆś≠•ŤŅźŤ°ĆÔľĆClusteringšľöś∑ĽŚä†šļÜšłÄÁßćśĖįÁöĄREPLACEśďćšĹúÁĪĽŚěčԾƍĮ•śďćšĹúÁĪĽŚěčŚįÜŚú®HudiŚÖÉśēįśćģśó∂ťóīŤĹīšł≠ś†áŤģįClusteringśďćšĹú„Äā. śÄĽšĹďŤÄĆŤ®ÄClustering Śú® DOCKER šł≠ŤŅźŤ°Ć APACHE PHOENIX ŚĻ∂ŚźĮÁĒ®ŤŅúÁ®čŤįÉŤĮē ‚ĶTRANSLATETHIS PAGE
śúÄŤŅĎÁĒĪšļéŚ∑•šĹúśĖĻťĚĘÁöĄŚéüŚõ†ťúÄŤ¶ĀŤß£śěź Apache Phoenix ŚļēŚĪāÁöĄŚéüŚßčśĖᚼ∂ԾƚĻüŚįĪśėĮŚ≠ėŚú® HDFS šłäÁöĄ HFile„ÄāšĹÜśėĮÁĒĪšļé Phoenix śúȍᙍļęÁöĄšłÄŚ•óśēįśćģÁľĖÁ†ĀśĖĻŚľŹÔľĆšĹÜśėĮÁĒĪšļéśú¨šļļŚĮĻ Phoenix ŤŅôŚ•óś†Ļśú¨ŚįĪšłćÁÜüśāČԾƜČÄšĽ•ŚŹ™ŤÉōᙌ∑ĪŚéĽÁúčÁõłŚÖ≥šĽ£Á†Ā„ÄāšĹÜśėĮApache Phoenix
śėĮšł™Ś§ßŚ∑•Á®čŚēäԾƚłćŚŹĮŤÉĹšłÄšł™šłÄšł™śĖᚼ∂ŚéĽśČĺÁöĄÔľĆŤŅôšľöÁõłŚĹďÁöĄśÖĘ„Äā HADOOP„ÄĀHIVEÁ≠ČšłčŤĹĹŚúįŚĚÄ Centos 7.5 YUMŚģČŤ£ÖMysql; CentOSšłčŤĹĹŚúįŚĚÄ; FedorašłčŤĹĹŚúįŚĚÄ; First Steps to Scala; GitŚģČŤ£Ö; GoogleśúÄśĖįIP; Hadoop„ÄĀHiveÁ≠ČšłčŤĹĹŚúįŚĚÄ; HTTP Content-TypeŚłłÁĒ®šłÄŤßąŤ°® DOCKER ŚÖ•ťó®śēôÁ®čÔľöšŅģśĒĻťēúŚÉŹšĽďŚļďŚúįŚĚÄ ŚįÜ MySQL ÁöĄŚÖ®ťáŹśēįśćģšĽ•ŚąÜť°ĶÁöĄŚĹĘŚľŹŚĮľŚÖ•Śąį Apache Solr šł≠ 2018-08-07; Śú®Hivešł≠šĹŅÁĒ®Avro 2014-04-08 1ŤĮĄŤģļ; śó∂ŚąĽś≥®śĄŹWordPressÁĹĎÁęôÁöĄŚģČŚÖ® 2013-04-04; Keyšłļnullśó∂KafkaŚ¶āšĹēťÄČśč©ŚąÜŚĆļ(Partition) 2016-03-30 HadoopŚÖÉśēįśćģŚźąŚĻ∂ŚľāŚłłŚŹäŤß£ŚÜ≥śĖĻś≥ē 2014-04-23 2ŤĮĄŤģļ; Apache Hadoop 3.0.0-alpha1ś≠£ŚľŹŚŹĎŚłÉŚŹäŚÖ∂śõīśĖįšĽčÁĽć 2016-09-22 Ść≥ŚįÜŚŹĎŚłÉÁöĄ APACHE KAFKA 2.8 ŚįÜšłćťúÄŤ¶ĀšĺĚŤĶĖ ‚ĶTRANSLATE THISPAGE
Apache Kafka ÁöĄś†łŚŅÉŤģĺŤģ°śėĮśó•ŚŅóÔľąLogԾȂÄĒ‚ÄĒ šłÄšł™ÁģÄŚćēÁöĄśēįśćģÁĽďśěĄÔľĆšĹŅÁĒ®ť°ļŚļŹśďćšĹú„ÄāšĽ•śó•ŚŅóšłļšł≠ŚŅÉÁöĄŤģĺŤģ°Śł¶śĚ•šļÜťęėśēąÁöĄÁ£ĀÁõėÁľďŚÜ≤ŚíĆCPU
ÁľďŚ≠ėšĹŅÁĒ®„ÄĀťĘĄŚŹĖ„ÄĀťõ∂śč∑ŤīĚśēįśćģšľ†ŤĺďŚíĆŤģłŚ§öŚÖ∂šĽĖŚ•ĹŚ§ĄÔľĆšĽéŤÄĆšĹŅKafka
ŤÉĹŚ§üśŹźšĺõťęėśēąÁéáŚíĆŚźěŚźźťáŹÁöĄŚäüŤÉĹ„ÄāŚĮĻšļéťā£šļõŚąöśé•Ťß¶ Kafka ÁöĄšļļśĚ•ŤĮīԾƚłĽťĘėÔľątopicԾȚĽ•ŚŹäśŹźšļ§śó•ŚŅóÁöĄ APACHE SPARK šł≠śĒĮśĆĀÁöĄšłÉÁßć JOIN ÁĪĽŚěč śēįśćģŚąÜśěźšł≠ŚįÜšł§šł™śēįśćģťõÜŤŅõŤ°Ć Join śďćšĹúśėĮŚĺąŚłłŤßĀÁöĄŚúļśôĮ„ÄāśąĎŚú® ŤŅôÁĮá śĖáÁꆚł≠šĽčÁĽćšļÜ Spark śĒĮśĆĀÁöĄšļĒÁßć Join Á≠ĖÁē•ÔľĆśú¨śĖ᜹όįÜÁĽôŚ§ßŚģ∂šĽčÁĽćšłÄšłč Apache Spark šł≠śĒĮśĆĀÁöĄ Join ÁĪĽŚěčÔľąJoin TypeԾȄÄā ÁõģŚČć Apache Spark 3.0 ÁČąśú¨šł≠ԾƚłÄŚÖĪśĒĮśĆĀšĽ•šłčšłÉÁßć Join ÁĪĽŚěčÔľö INNER JOIN CROSS JOIN LEFT OUTER JOIN RIGHT OUTER JOIN FULL OUTE ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for Fashion SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ Apache Spark 3.0 śėĮŚ¶āšĹēśŹźťęė SQL Ś∑•šĹúŤīüŤĹĹÁöĄśÄߍÉĹ. Śú®Śá†šĻéśČÄśúČŚ§ĄÁźÜŚ§ćśĚāśēįśćģÁöĄťĘÜŚüüÔľĆSpark Ś∑≤ÁĽŹŤŅÖťÄüśąźšłļśēįśćģŚíĆŚąÜśěźÁĒüŚĎĹŚĎ®śúüŚõĘťėüÁöĄšļčŚģěšłäÁöĄŚąÜŚłÉŚľŹŤģ°Áģóś°Üśě∂„Äā.Spark 3.0
śúÄŚŹóśúüŚĺÖÁöĄÁČĻśÄßšĻ蚳ĜėĮśĖįÁöĄŤá™ťÄāŚļĒśü•ŤĮĘśČߍ°Ćś°Üśě∂ (Adaptive Query ExecutionÔľĆAQE)ԾƍĮ•ś°Üśě∂Ťß£ŚÜ≥šļÜŤģłŚ§ö Spark SQL UBUNTU 10.04.4 LTSšłčŤĹĹŚúįŚĚÄ Ubuntu 10.04.4 LTSšłčŤĹĹŚúįŚĚÄ. ŚąÜšļę ( 0) śĖáÁę†ÁõģŚĹē 1 Select an image. 1.1 Desktop CD. 1.2 Server install CD. 1.3 Alternate install CD. This directory contains the most frequently downloaded Ubuntu images. Other images, including DVDs and source CDs, may be available on the cdimage server. ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄ ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄÔľö śõīśĖįśó∂ťóīÔľö2015ŚĻī4śúą11śó• 11:05:06 ŚļŹŚŹ∑ ŚúįŚĚÄ ÁęĮŚŹ£ ŚõĹŚģ∂ ÁĪĽŚěč(ŚĆŅŚźćŚļ¶) Áä∂śÄĀ ŚÖ®śĶč 1 152.26.69.36 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 2 152.26.69.37 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 3 152.26.69.35 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤śĶčŤĮē 4
APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
JAVAŤé∑ŚŹĖŚ∑•Á®čŤ∑ĮŚĺĄÁöĄŚá†ÁßćśĖĻś≥ē ‚Äď Á¨¨šļĒÁßćÔľö. System.out.println ( System.getProperty ("java.class.path")); ÁĽďśěúÔľö. C:\Documents and Settings\Administrator\workspace\projectName\bin. Ťé∑ŚŹĖŚĹďŚČćŚ∑•Á®čŤ∑ĮŚĺĄ. śú¨ŚćöŚģĘśĖáÁꆝô§ÁČĻŚąęŚ£įśėéԾƌ֮ťÉ®ťÉĹśėĮŚéüŚąõÔľĀ. ŚéüŚąõśĖáÁę†ÁČąśĚÉŚĹíŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģÔľą ŤŅáŚĺÄŤģįŚŅÜ ÔľČśČÄśúČԾƜú™ÁĽŹŤģłŚŹĮšłćŚĺóŤĹ¨ŤĹĹ„Äā. śú¨śĖá HBASE ŚćŹŚ§ĄÁźÜŚô®ŚÖ•ťó®ŚŹäŚģěśąė HBase ŚíĆ MapReduce śúČŚĺąťęėÁöĄťõÜśąźÔľĆśąĎšĽ¨ŚŹĮšĽ•šĹŅÁĒ® MRŚĮĻŚ≠ėŚā®Śú® HBase
šł≠ÁöĄśēįśćģŤŅõŤ°ĆŚąÜŚłÉŚľŹŤģ°Áģó„ÄāšĹÜśėĮŚú®ŚĺąŚ§öśÉÖŚÜĶšłčԾƚĺ茶āÁģÄŚćēÁöĄŚä†ś≥ēŤģ°ÁģóśąĖŤÄÖŤĀöŚźąśďćšĹúÔľąśĪāŚíĆ„ÄĀŤģ°śēįÁ≠ČÔľČԾƌ¶āśěúŤÉĹŚ§üŚįÜŤŅôšļõŤģ°Áģóśé®ťÄĀŚąį RegionServerԾƍŅôŚįÜŚ§ßŚ§ßŚáŹŚįĎśúćŚä°Śô®ŚíĆŚģĘśą∑ÁöĄÁöĄśēįśćģťÄöšŅ°ŚľÄťĒÄԾƚĽéŤÄĆśŹźťęė HBase ÁöĄŤģ°ÁģóśÄߍÉĹԾƍŅôŚįĪśėĮśú¨śĖ፶ĀšĽčÁĽćÁöĄ Śú® DOCKER šł≠ŤŅźŤ°Ć APACHE PHOENIX ŚĻ∂ŚźĮÁĒ®ŤŅúÁ®čŤįÉŤĮē śúÄŤŅĎÁĒĪšļéŚ∑•šĹúśĖĻťĚĘÁöĄŚéüŚõ†ťúÄŤ¶ĀŤß£śěź Apache Phoenix ŚļēŚĪāÁöĄŚéüŚßčśĖᚼ∂ԾƚĻüŚįĪśėĮŚ≠ėŚú® HDFS šłäÁöĄ HFile„ÄāšĹÜśėĮÁĒĪšļé Phoenix śúȍᙍļęÁöĄšłÄŚ•óśēįśćģÁľĖÁ†ĀśĖĻŚľŹÔľĆšĹÜśėĮÁĒĪšļéśú¨šļļŚĮĻ Phoenix ŤŅôŚ•óś†Ļśú¨ŚįĪšłćÁÜüśāČԾƜČÄšĽ•ŚŹ™ŤÉōᙌ∑ĪŚéĽÁúčÁõłŚÖ≥šĽ£Á†Ā„ÄāšĹÜśėĮApache Phoenix
śėĮšł™Ś§ßŚ∑•Á®čŚēäԾƚłćŚŹĮŤÉĹšłÄšł™šłÄšł™śĖᚼ∂ŚéĽśČĺÁöĄÔľĆŤŅôšľöÁõłŚĹďÁöĄśÖĘ„Äā Ść≥ŚįÜŚŹĎŚłÉÁöĄ APACHE KAFKA 2.8 ŚįÜšłćťúÄŤ¶ĀšĺĚŤĶĖ ‚ĶTRANSLATE THISPAGE
Apache Kafka ÁöĄś†łŚŅÉŤģĺŤģ°śėĮśó•ŚŅóÔľąLogԾȂÄĒ‚ÄĒ šłÄšł™ÁģÄŚćēÁöĄśēįśćģÁĽďśěĄÔľĆšĹŅÁĒ®ť°ļŚļŹśďćšĹú„ÄāšĽ•śó•ŚŅóšłļšł≠ŚŅÉÁöĄŤģĺŤģ°Śł¶śĚ•šļÜťęėśēąÁöĄÁ£ĀÁõėÁľďŚÜ≤ŚíĆCPU
ÁľďŚ≠ėšĹŅÁĒ®„ÄĀťĘĄŚŹĖ„ÄĀťõ∂śč∑ŤīĚśēįśćģšľ†ŤĺďŚíĆŤģłŚ§öŚÖ∂šĽĖŚ•ĹŚ§ĄÔľĆšĽéŤÄĆšĹŅKafka
ŤÉĹŚ§üśŹźšĺõťęėśēąÁéáŚíĆŚźěŚźźťáŹÁöĄŚäüŤÉĹ„ÄāŚĮĻšļéťā£šļõŚąöśé•Ťß¶ Kafka ÁöĄšļļśĚ•ŤĮīԾƚłĽťĘėÔľątopicԾȚĽ•ŚŹäśŹźšļ§śó•ŚŅóÁöĄ ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for Fashion SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ Apache Spark 3.0 śėĮŚ¶āšĹēśŹźťęė SQL Ś∑•šĹúŤīüŤĹĹÁöĄśÄߍÉĹ. Śú®Śá†šĻéśČÄśúČŚ§ĄÁźÜŚ§ćśĚāśēįśćģÁöĄťĘÜŚüüÔľĆSpark Ś∑≤ÁĽŹŤŅÖťÄüśąźšłļśēįśćģŚíĆŚąÜśěźÁĒüŚĎĹŚĎ®śúüŚõĘťėüÁöĄšļčŚģěšłäÁöĄŚąÜŚłÉŚľŹŤģ°Áģóś°Üśě∂„Äā.Spark 3.0
śúÄŚŹóśúüŚĺÖÁöĄÁČĻśÄßšĻ蚳ĜėĮśĖįÁöĄŤá™ťÄāŚļĒśü•ŤĮĘśČߍ°Ćś°Üśě∂ (Adaptive Query ExecutionÔľĆAQE)ԾƍĮ•ś°Üśě∂Ťß£ŚÜ≥šļÜŤģłŚ§ö Spark SQL UBUNTU 10.04.4 LTSšłčŤĹĹŚúįŚĚÄ Ubuntu 10.04.4 LTSšłčŤĹĹŚúįŚĚÄ. ŚąÜšļę ( 0) śĖáÁę†ÁõģŚĹē 1 Select an image. 1.1 Desktop CD. 1.2 Server install CD. 1.3 Alternate install CD. This directory contains the most frequently downloaded Ubuntu images. Other images, including DVDs and source CDs, may be available on the cdimage server. ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄ ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄÔľö śõīśĖįśó∂ťóīÔľö2015ŚĻī4śúą11śó• 11:05:06 ŚļŹŚŹ∑ ŚúįŚĚÄ ÁęĮŚŹ£ ŚõĹŚģ∂ ÁĪĽŚěč(ŚĆŅŚźćŚļ¶) Áä∂śÄĀ ŚÖ®śĶč 1 152.26.69.36 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 2 152.26.69.37 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 3 152.26.69.35 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤śĶčŤĮē 4
APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
JAVAŤé∑ŚŹĖŚ∑•Á®čŤ∑ĮŚĺĄÁöĄŚá†ÁßćśĖĻś≥ē ‚Äď Á¨¨šļĒÁßćÔľö. System.out.println ( System.getProperty ("java.class.path")); ÁĽďśěúÔľö. C:\Documents and Settings\Administrator\workspace\projectName\bin. Ťé∑ŚŹĖŚĹďŚČćŚ∑•Á®čŤ∑ĮŚĺĄ. śú¨ŚćöŚģĘśĖáÁꆝô§ÁČĻŚąęŚ£įśėéԾƌ֮ťÉ®ťÉĹśėĮŚéüŚąõÔľĀ. ŚéüŚąõśĖáÁę†ÁČąśĚÉŚĹíŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģÔľą ŤŅáŚĺÄŤģįŚŅÜ ÔľČśČÄśúČԾƜú™ÁĽŹŤģłŚŹĮšłćŚĺóŤĹ¨ŤĹĹ„Äā. śú¨śĖá HBASE ŚćŹŚ§ĄÁźÜŚô®ŚÖ•ťó®ŚŹäŚģěśąė HBase ŚíĆ MapReduce śúČŚĺąťęėÁöĄťõÜśąźÔľĆśąĎšĽ¨ŚŹĮšĽ•šĹŅÁĒ® MRŚĮĻŚ≠ėŚā®Śú® HBase
šł≠ÁöĄśēįśćģŤŅõŤ°ĆŚąÜŚłÉŚľŹŤģ°Áģó„ÄāšĹÜśėĮŚú®ŚĺąŚ§öśÉÖŚÜĶšłčԾƚĺ茶āÁģÄŚćēÁöĄŚä†ś≥ēŤģ°ÁģóśąĖŤÄÖŤĀöŚźąśďćšĹúÔľąśĪāŚíĆ„ÄĀŤģ°śēįÁ≠ČÔľČԾƌ¶āśěúŤÉĹŚ§üŚįÜŤŅôšļõŤģ°Áģóśé®ťÄĀŚąį RegionServerԾƍŅôŚįÜŚ§ßŚ§ßŚáŹŚįĎśúćŚä°Śô®ŚíĆŚģĘśą∑ÁöĄÁöĄśēįśćģťÄöšŅ°ŚľÄťĒÄԾƚĽéŤÄĆśŹźťęė HBase ÁöĄŤģ°ÁģóśÄߍÉĹԾƍŅôŚįĪśėĮśú¨śĖ፶ĀšĽčÁĽćÁöĄ Śú® DOCKER šł≠ŤŅźŤ°Ć APACHE PHOENIX ŚĻ∂ŚźĮÁĒ®ŤŅúÁ®čŤįÉŤĮē śúÄŤŅĎÁĒĪšļéŚ∑•šĹúśĖĻťĚĘÁöĄŚéüŚõ†ťúÄŤ¶ĀŤß£śěź Apache Phoenix ŚļēŚĪāÁöĄŚéüŚßčśĖᚼ∂ԾƚĻüŚįĪśėĮŚ≠ėŚú® HDFS šłäÁöĄ HFile„ÄāšĹÜśėĮÁĒĪšļé Phoenix śúȍᙍļęÁöĄšłÄŚ•óśēįśćģÁľĖÁ†ĀśĖĻŚľŹÔľĆšĹÜśėĮÁĒĪšļéśú¨šļļŚĮĻ Phoenix ŤŅôŚ•óś†Ļśú¨ŚįĪšłćÁÜüśāČԾƜČÄšĽ•ŚŹ™ŤÉōᙌ∑ĪŚéĽÁúčÁõłŚÖ≥šĽ£Á†Ā„ÄāšĹÜśėĮApache Phoenix
śėĮšł™Ś§ßŚ∑•Á®čŚēäԾƚłćŚŹĮŤÉĹšłÄšł™šłÄšł™śĖᚼ∂ŚéĽśČĺÁöĄÔľĆŤŅôšľöÁõłŚĹďÁöĄśÖĘ„Äā Ść≥ŚįÜŚŹĎŚłÉÁöĄ APACHE KAFKA 2.8 ŚįÜšłćťúÄŤ¶ĀšĺĚŤĶĖ ‚ĶTRANSLATE THISPAGE
Apache Kafka ÁöĄś†łŚŅÉŤģĺŤģ°śėĮśó•ŚŅóÔľąLogԾȂÄĒ‚ÄĒ šłÄšł™ÁģÄŚćēÁöĄśēįśćģÁĽďśěĄÔľĆšĹŅÁĒ®ť°ļŚļŹśďćšĹú„ÄāšĽ•śó•ŚŅóšłļšł≠ŚŅÉÁöĄŤģĺŤģ°Śł¶śĚ•šļÜťęėśēąÁöĄÁ£ĀÁõėÁľďŚÜ≤ŚíĆCPU
ÁľďŚ≠ėšĹŅÁĒ®„ÄĀťĘĄŚŹĖ„ÄĀťõ∂śč∑ŤīĚśēįśćģšľ†ŤĺďŚíĆŤģłŚ§öŚÖ∂šĽĖŚ•ĹŚ§ĄÔľĆšĽéŤÄĆšĹŅKafka
ŤÉĹŚ§üśŹźšĺõťęėśēąÁéáŚíĆŚźěŚźźťáŹÁöĄŚäüŤÉĹ„ÄāŚĮĻšļéťā£šļõŚąöśé•Ťß¶ Kafka ÁöĄšļļśĚ•ŤĮīԾƚłĽťĘėÔľątopicԾȚĽ•ŚŹäśŹźšļ§śó•ŚŅóÁöĄ SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ ŤĶ∂Śú® Data + AI Summit 2021 šĻčŚČćÔľĆDelta Lake 1.0.0 ťáćÁ£ÖŚŹĎŚłÉԾƍŅôšł™ÁČąśú¨śėĮŚüļšļé Spark 3.1 ÁöĄÔľĆŚł¶śĚ•šļÜŤģłŚ§öśĖįÁČĻśÄß„Äāśú¨śĖáŚįÜÁĽďŚźą Michael Armbrust Ś§ßÁČõŚú® Data + AI Summit 2021 ÁöĄśľĒŤģ≤„ÄäAnnouncing Delta Lake 1.0„ÄčśĚ•šĽčÁĽć Delta Lake 1.0.0 ÁČąśú¨ÁöĄšłÄšļõťá捶ĀÁöĄśĖįÁČĻśÄß„Äā šļĒśúą ‚Äď 2021 ‚Äď ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGE ŤĶ∂Śú® Data + AI Summit 2021 šĻčŚČćÔľĆDelta Lake 1.0.0 ťáćÁ£ÖŚŹĎŚłÉԾƍŅôšł™ÁČąśú¨śėĮŚüļšļé Spark 3.1 ÁöĄÔľĆŚł¶śĚ•šļÜŤģłŚ§öśĖįÁČĻśÄß„Äāśú¨śĖáŚįÜÁĽďŚźą Michael Armbrust Ś§ßÁČõŚú® Data + AI Summit 2021 ÁöĄśľĒŤģ≤„ÄäAnnouncing Delta Lake 1.0„ÄčśĚ•šĽčÁĽć Delta Lake 1.0.0 ÁČąśú¨ÁöĄšłÄšļõťá捶ĀÁöĄśĖįÁČĻśÄß„Äā DASHBOARD - ACE ADMIN(BOOTSTRAPŚźéŚŹįÁģ°ÁźÜÁ≥ĽÁĽüś®°ÁČąACEšłčŤĹĹ) Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque commodo massa sed ipsum porttitor facilisis. HBASE ‚Äď ŤŅáŚĺÄŤģįŚŅÜ-PAGE 3TRANSLATE THIS PAGE ŤÉĆśôĮťöŹÁĚÄ Apache HBase Śú®ŚźĄšł™ťĘÜŚüüÁöĄŚĻŅś≥õŚļĒÁĒ®ÔľĆŚú® HBase ŤŅźÁĽīśąĖŚļĒÁĒ®ÁöĄŤŅáÁ®čšł≠śąĎšĽ¨ŚŹĮŤÉĹšľöťĀጹįŤŅôś†∑ÁöĄťóģťĘėÔľöŚźĆšłÄšł™HBase
ťõÜÁ姚ĹŅÁĒ®ÁöĄÁĒ®śą∑Ť∂äśĚ•Ť∂䌧öԾƚłćŚźĆÁĒ®śą∑šĻčťóīÁöĄŤĮĽŚÜôśąĖŤÄÖšłćŚźĆŤ°®ÁöĄ compaction„ÄĀregion splits śďćšĹúŚŹĮŤÉĹŚĮĻŚÖ∂šĽĖÁĒ®śą∑śąĖŤ°®šļßÁĒüšļÜŚĹĪŚďć„Äā APACHE HUDI CLUSTERING śēįśćģŚłÉŚĪÄŚäüŤÉĹšĽčÁĽć šłļŤÉĹŚ§üśĒĮśĆĀŚŅęťÄüśĎĄŚŹĖÁöĄŚźĆśó∂šłćŚĹĪŚďćśü•ŤĮĘśÄߍÉĹԾƜąĎšĽ¨ŚľēŚÖ•šļÜClusteringśúćŚä°śĚ•ťáćŚÜôśēįśćģšĽ•šľėŚĆĖHudiśēįśćģśĻĖśĖᚼ∂ÁöĄŚłÉŚĪÄ„Äā. ClusteringśúćŚä°ŚŹĮšĽ•Śľāś≠•śąĖŚźĆś≠•ŤŅźŤ°ĆÔľĆClusteringšľöś∑ĽŚä†šļÜšłÄÁßćśĖįÁöĄREPLACEśďćšĹúÁĪĽŚěčԾƍĮ•śďćšĹúÁĪĽŚěčŚįÜŚú®HudiŚÖÉśēįśćģśó∂ťóīŤĹīšł≠ś†áŤģįClusteringśďćšĹú„Äā. śÄĽšĹďŤÄĆŤ®ÄClustering Śú® DOCKER šł≠ŤŅźŤ°Ć APACHE PHOENIX ŚĻ∂ŚźĮÁĒ®ŤŅúÁ®čŤįÉŤĮē ‚ĶTRANSLATETHIS PAGE
śúÄŤŅĎÁĒĪšļéŚ∑•šĹúśĖĻťĚĘÁöĄŚéüŚõ†ťúÄŤ¶ĀŤß£śěź Apache Phoenix ŚļēŚĪāÁöĄŚéüŚßčśĖᚼ∂ԾƚĻüŚįĪśėĮŚ≠ėŚú® HDFS šłäÁöĄ HFile„ÄāšĹÜśėĮÁĒĪšļé Phoenix śúȍᙍļęÁöĄšłÄŚ•óśēįśćģÁľĖÁ†ĀśĖĻŚľŹÔľĆšĹÜśėĮÁĒĪšļéśú¨šļļŚĮĻ Phoenix ŤŅôŚ•óś†Ļśú¨ŚįĪšłćÁÜüśāČԾƜČÄšĽ•ŚŹ™ŤÉōᙌ∑ĪŚéĽÁúčÁõłŚÖ≥šĽ£Á†Ā„ÄāšĹÜśėĮApache Phoenix
śėĮšł™Ś§ßŚ∑•Á®čŚēäԾƚłćŚŹĮŤÉĹšłÄšł™šłÄšł™śĖᚼ∂ŚéĽśČĺÁöĄÔľĆŤŅôšľöÁõłŚĹďÁöĄśÖĘ„Äā HADOOP„ÄĀHIVEÁ≠ČšłčŤĹĹŚúįŚĚÄ Centos 7.5 YUMŚģČŤ£ÖMysql; CentOSšłčŤĹĹŚúįŚĚÄ; FedorašłčŤĹĹŚúįŚĚÄ; First Steps to Scala; GitŚģČŤ£Ö; GoogleśúÄśĖįIP; Hadoop„ÄĀHiveÁ≠ČšłčŤĹĹŚúįŚĚÄ; HTTP Content-TypeŚłłÁĒ®šłÄŤßąŤ°® DOCKER ŚÖ•ťó®śēôÁ®čÔľöšŅģśĒĻťēúŚÉŹšĽďŚļďŚúįŚĚÄ ŚįÜ MySQL ÁöĄŚÖ®ťáŹśēįśćģšĽ•ŚąÜť°ĶÁöĄŚĹĘŚľŹŚĮľŚÖ•Śąį Apache Solr šł≠ 2018-08-07; Śú®Hivešł≠šĹŅÁĒ®Avro 2014-04-08 1ŤĮĄŤģļ; śó∂ŚąĽś≥®śĄŹWordPressÁĹĎÁęôÁöĄŚģČŚÖ® 2013-04-04; Keyšłļnullśó∂KafkaŚ¶āšĹēťÄČśč©ŚąÜŚĆļ(Partition) 2016-03-30 HadoopŚÖÉśēįśćģŚźąŚĻ∂ŚľāŚłłŚŹäŤß£ŚÜ≥śĖĻś≥ē 2014-04-23 2ŤĮĄŤģļ; Apache Hadoop 3.0.0-alpha1ś≠£ŚľŹŚŹĎŚłÉŚŹäŚÖ∂śõīśĖįšĽčÁĽć 2016-09-22 Ść≥ŚįÜŚŹĎŚłÉÁöĄ APACHE KAFKA 2.8 ŚįÜšłćťúÄŤ¶ĀšĺĚŤĶĖ ‚ĶTRANSLATE THISPAGE
Apache Kafka ÁöĄś†łŚŅÉŤģĺŤģ°śėĮśó•ŚŅóÔľąLogԾȂÄĒ‚ÄĒ šłÄšł™ÁģÄŚćēÁöĄśēįśćģÁĽďśěĄÔľĆšĹŅÁĒ®ť°ļŚļŹśďćšĹú„ÄāšĽ•śó•ŚŅóšłļšł≠ŚŅÉÁöĄŤģĺŤģ°Śł¶śĚ•šļÜťęėśēąÁöĄÁ£ĀÁõėÁľďŚÜ≤ŚíĆCPU
ÁľďŚ≠ėšĹŅÁĒ®„ÄĀťĘĄŚŹĖ„ÄĀťõ∂śč∑ŤīĚśēįśćģšľ†ŤĺďŚíĆŤģłŚ§öŚÖ∂šĽĖŚ•ĹŚ§ĄÔľĆšĽéŤÄĆšĹŅKafka
ŤÉĹŚ§üśŹźšĺõťęėśēąÁéáŚíĆŚźěŚźźťáŹÁöĄŚäüŤÉĹ„ÄāŚĮĻšļéťā£šļõŚąöśé•Ťß¶ Kafka ÁöĄšļļśĚ•ŤĮīԾƚłĽťĘėÔľątopicԾȚĽ•ŚŹäśŹźšļ§śó•ŚŅóÁöĄ APACHE SPARK šł≠śĒĮśĆĀÁöĄšłÉÁßć JOIN ÁĪĽŚěč śēįśćģŚąÜśěźšł≠ŚįÜšł§šł™śēįśćģťõÜŤŅõŤ°Ć Join śďćšĹúśėĮŚĺąŚłłŤßĀÁöĄŚúļśôĮ„ÄāśąĎŚú® ŤŅôÁĮá śĖáÁꆚł≠šĽčÁĽćšļÜ Spark śĒĮśĆĀÁöĄšļĒÁßć Join Á≠ĖÁē•ÔľĆśú¨śĖ᜹όįÜÁĽôŚ§ßŚģ∂šĽčÁĽćšłÄšłč Apache Spark šł≠śĒĮśĆĀÁöĄ Join ÁĪĽŚěčÔľąJoin TypeԾȄÄā ÁõģŚČć Apache Spark 3.0 ÁČąśú¨šł≠ԾƚłÄŚÖĪśĒĮśĆĀšĽ•šłčšłÉÁßć Join ÁĪĽŚěčÔľö INNER JOIN CROSS JOIN LEFT OUTER JOIN RIGHT OUTER JOIN FULL OUTE ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for Fashion SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ Apache Spark 3.0 śėĮŚ¶āšĹēśŹźťęė SQL Ś∑•šĹúŤīüŤĹĹÁöĄśÄߍÉĹ. Śú®Śá†šĻéśČÄśúČŚ§ĄÁźÜŚ§ćśĚāśēįśćģÁöĄťĘÜŚüüÔľĆSpark Ś∑≤ÁĽŹŤŅÖťÄüśąźšłļśēįśćģŚíĆŚąÜśěźÁĒüŚĎĹŚĎ®śúüŚõĘťėüÁöĄšļčŚģěšłäÁöĄŚąÜŚłÉŚľŹŤģ°Áģóś°Üśě∂„Äā.Spark 3.0
śúÄŚŹóśúüŚĺÖÁöĄÁČĻśÄßšĻ蚳ĜėĮśĖįÁöĄŤá™ťÄāŚļĒśü•ŤĮĘśČߍ°Ćś°Üśě∂ (Adaptive Query ExecutionÔľĆAQE)ԾƍĮ•ś°Üśě∂Ťß£ŚÜ≥šļÜŤģłŚ§ö Spark SQL UBUNTU 10.04.4 LTSšłčŤĹĹŚúįŚĚÄ Ubuntu 10.04.4 LTSšłčŤĹĹŚúįŚĚÄ. ŚąÜšļę ( 0) śĖáÁę†ÁõģŚĹē 1 Select an image. 1.1 Desktop CD. 1.2 Server install CD. 1.3 Alternate install CD. This directory contains the most frequently downloaded Ubuntu images. Other images, including DVDs and source CDs, may be available on the cdimage server. ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄ ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄÔľö śõīśĖįśó∂ťóīÔľö2015ŚĻī4śúą11śó• 11:05:06 ŚļŹŚŹ∑ ŚúįŚĚÄ ÁęĮŚŹ£ ŚõĹŚģ∂ ÁĪĽŚěč(ŚĆŅŚźćŚļ¶) Áä∂śÄĀ ŚÖ®śĶč 1 152.26.69.36 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 2 152.26.69.37 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 3 152.26.69.35 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤śĶčŤĮē 4
APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
JAVAŤé∑ŚŹĖŚ∑•Á®čŤ∑ĮŚĺĄÁöĄŚá†ÁßćśĖĻś≥ē ‚Äď Á¨¨šļĒÁßćÔľö. System.out.println ( System.getProperty ("java.class.path")); ÁĽďśěúÔľö. C:\Documents and Settings\Administrator\workspace\projectName\bin. Ťé∑ŚŹĖŚĹďŚČćŚ∑•Á®čŤ∑ĮŚĺĄ. śú¨ŚćöŚģĘśĖáÁꆝô§ÁČĻŚąęŚ£įśėéԾƌ֮ťÉ®ťÉĹśėĮŚéüŚąõÔľĀ. ŚéüŚąõśĖáÁę†ÁČąśĚÉŚĹíŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģÔľą ŤŅáŚĺÄŤģįŚŅÜ ÔľČśČÄśúČԾƜú™ÁĽŹŤģłŚŹĮšłćŚĺóŤĹ¨ŤĹĹ„Äā. śú¨śĖá HBASE ŚćŹŚ§ĄÁźÜŚô®ŚÖ•ťó®ŚŹäŚģěśąė HBase ŚíĆ MapReduce śúČŚĺąťęėÁöĄťõÜśąźÔľĆśąĎšĽ¨ŚŹĮšĽ•šĹŅÁĒ® MRŚĮĻŚ≠ėŚā®Śú® HBase
šł≠ÁöĄśēįśćģŤŅõŤ°ĆŚąÜŚłÉŚľŹŤģ°Áģó„ÄāšĹÜśėĮŚú®ŚĺąŚ§öśÉÖŚÜĶšłčԾƚĺ茶āÁģÄŚćēÁöĄŚä†ś≥ēŤģ°ÁģóśąĖŤÄÖŤĀöŚźąśďćšĹúÔľąśĪāŚíĆ„ÄĀŤģ°śēįÁ≠ČÔľČԾƌ¶āśěúŤÉĹŚ§üŚįÜŤŅôšļõŤģ°Áģóśé®ťÄĀŚąį RegionServerԾƍŅôŚįÜŚ§ßŚ§ßŚáŹŚįĎśúćŚä°Śô®ŚíĆŚģĘśą∑ÁöĄÁöĄśēįśćģťÄöšŅ°ŚľÄťĒÄԾƚĽéŤÄĆśŹźťęė HBase ÁöĄŤģ°ÁģóśÄߍÉĹԾƍŅôŚįĪśėĮśú¨śĖ፶ĀšĽčÁĽćÁöĄ Śú® DOCKER šł≠ŤŅźŤ°Ć APACHE PHOENIX ŚĻ∂ŚźĮÁĒ®ŤŅúÁ®čŤįÉŤĮē śúÄŤŅĎÁĒĪšļéŚ∑•šĹúśĖĻťĚĘÁöĄŚéüŚõ†ťúÄŤ¶ĀŤß£śěź Apache Phoenix ŚļēŚĪāÁöĄŚéüŚßčśĖᚼ∂ԾƚĻüŚįĪśėĮŚ≠ėŚú® HDFS šłäÁöĄ HFile„ÄāšĹÜśėĮÁĒĪšļé Phoenix śúȍᙍļęÁöĄšłÄŚ•óśēįśćģÁľĖÁ†ĀśĖĻŚľŹÔľĆšĹÜśėĮÁĒĪšļéśú¨šļļŚĮĻ Phoenix ŤŅôŚ•óś†Ļśú¨ŚįĪšłćÁÜüśāČԾƜČÄšĽ•ŚŹ™ŤÉōᙌ∑ĪŚéĽÁúčÁõłŚÖ≥šĽ£Á†Ā„ÄāšĹÜśėĮApache Phoenix
śėĮšł™Ś§ßŚ∑•Á®čŚēäԾƚłćŚŹĮŤÉĹšłÄšł™šłÄšł™śĖᚼ∂ŚéĽśČĺÁöĄÔľĆŤŅôšľöÁõłŚĹďÁöĄśÖĘ„Äā Ść≥ŚįÜŚŹĎŚłÉÁöĄ APACHE KAFKA 2.8 ŚįÜšłćťúÄŤ¶ĀšĺĚŤĶĖ ‚ĶTRANSLATE THISPAGE
Apache Kafka ÁöĄś†łŚŅÉŤģĺŤģ°śėĮśó•ŚŅóÔľąLogԾȂÄĒ‚ÄĒ šłÄšł™ÁģÄŚćēÁöĄśēįśćģÁĽďśěĄÔľĆšĹŅÁĒ®ť°ļŚļŹśďćšĹú„ÄāšĽ•śó•ŚŅóšłļšł≠ŚŅÉÁöĄŤģĺŤģ°Śł¶śĚ•šļÜťęėśēąÁöĄÁ£ĀÁõėÁľďŚÜ≤ŚíĆCPU
ÁľďŚ≠ėšĹŅÁĒ®„ÄĀťĘĄŚŹĖ„ÄĀťõ∂śč∑ŤīĚśēįśćģšľ†ŤĺďŚíĆŤģłŚ§öŚÖ∂šĽĖŚ•ĹŚ§ĄÔľĆšĽéŤÄĆšĹŅKafka
ŤÉĹŚ§üśŹźšĺõťęėśēąÁéáŚíĆŚźěŚźźťáŹÁöĄŚäüŤÉĹ„ÄāŚĮĻšļéťā£šļõŚąöśé•Ťß¶ Kafka ÁöĄšļļśĚ•ŤĮīԾƚłĽťĘėÔľątopicԾȚĽ•ŚŹäśŹźšļ§śó•ŚŅóÁöĄ ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for Fashion SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ Apache Spark 3.0 śėĮŚ¶āšĹēśŹźťęė SQL Ś∑•šĹúŤīüŤĹĹÁöĄśÄߍÉĹ. Śú®Śá†šĻéśČÄśúČŚ§ĄÁźÜŚ§ćśĚāśēįśćģÁöĄťĘÜŚüüÔľĆSpark Ś∑≤ÁĽŹŤŅÖťÄüśąźšłļśēįśćģŚíĆŚąÜśěźÁĒüŚĎĹŚĎ®śúüŚõĘťėüÁöĄšļčŚģěšłäÁöĄŚąÜŚłÉŚľŹŤģ°Áģóś°Üśě∂„Äā.Spark 3.0
śúÄŚŹóśúüŚĺÖÁöĄÁČĻśÄßšĻ蚳ĜėĮśĖįÁöĄŤá™ťÄāŚļĒśü•ŤĮĘśČߍ°Ćś°Üśě∂ (Adaptive Query ExecutionÔľĆAQE)ԾƍĮ•ś°Üśě∂Ťß£ŚÜ≥šļÜŤģłŚ§ö Spark SQL UBUNTU 10.04.4 LTSšłčŤĹĹŚúįŚĚÄ Ubuntu 10.04.4 LTSšłčŤĹĹŚúįŚĚÄ. ŚąÜšļę ( 0) śĖáÁę†ÁõģŚĹē 1 Select an image. 1.1 Desktop CD. 1.2 Server install CD. 1.3 Alternate install CD. This directory contains the most frequently downloaded Ubuntu images. Other images, including DVDs and source CDs, may be available on the cdimage server. ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄ ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄÔľö śõīśĖįśó∂ťóīÔľö2015ŚĻī4śúą11śó• 11:05:06 ŚļŹŚŹ∑ ŚúįŚĚÄ ÁęĮŚŹ£ ŚõĹŚģ∂ ÁĪĽŚěč(ŚĆŅŚźćŚļ¶) Áä∂śÄĀ ŚÖ®śĶč 1 152.26.69.36 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 2 152.26.69.37 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 3 152.26.69.35 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤śĶčŤĮē 4
APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
JAVAŤé∑ŚŹĖŚ∑•Á®čŤ∑ĮŚĺĄÁöĄŚá†ÁßćśĖĻś≥ē ‚Äď Á¨¨šļĒÁßćÔľö. System.out.println ( System.getProperty ("java.class.path")); ÁĽďśěúÔľö. C:\Documents and Settings\Administrator\workspace\projectName\bin. Ťé∑ŚŹĖŚĹďŚČćŚ∑•Á®čŤ∑ĮŚĺĄ. śú¨ŚćöŚģĘśĖáÁꆝô§ÁČĻŚąęŚ£įśėéԾƌ֮ťÉ®ťÉĹśėĮŚéüŚąõÔľĀ. ŚéüŚąõśĖáÁę†ÁČąśĚÉŚĹíŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģÔľą ŤŅáŚĺÄŤģįŚŅÜ ÔľČśČÄśúČԾƜú™ÁĽŹŤģłŚŹĮšłćŚĺóŤĹ¨ŤĹĹ„Äā. śú¨śĖá HBASE ŚćŹŚ§ĄÁźÜŚô®ŚÖ•ťó®ŚŹäŚģěśąė HBase ŚíĆ MapReduce śúČŚĺąťęėÁöĄťõÜśąźÔľĆśąĎšĽ¨ŚŹĮšĽ•šĹŅÁĒ® MRŚĮĻŚ≠ėŚā®Śú® HBase
šł≠ÁöĄśēįśćģŤŅõŤ°ĆŚąÜŚłÉŚľŹŤģ°Áģó„ÄāšĹÜśėĮŚú®ŚĺąŚ§öśÉÖŚÜĶšłčԾƚĺ茶āÁģÄŚćēÁöĄŚä†ś≥ēŤģ°ÁģóśąĖŤÄÖŤĀöŚźąśďćšĹúÔľąśĪāŚíĆ„ÄĀŤģ°śēįÁ≠ČÔľČԾƌ¶āśěúŤÉĹŚ§üŚįÜŤŅôšļõŤģ°Áģóśé®ťÄĀŚąį RegionServerԾƍŅôŚįÜŚ§ßŚ§ßŚáŹŚįĎśúćŚä°Śô®ŚíĆŚģĘśą∑ÁöĄÁöĄśēįśćģťÄöšŅ°ŚľÄťĒÄԾƚĽéŤÄĆśŹźťęė HBase ÁöĄŤģ°ÁģóśÄߍÉĹԾƍŅôŚįĪśėĮśú¨śĖ፶ĀšĽčÁĽćÁöĄ Śú® DOCKER šł≠ŤŅźŤ°Ć APACHE PHOENIX ŚĻ∂ŚźĮÁĒ®ŤŅúÁ®čŤįÉŤĮē śúÄŤŅĎÁĒĪšļéŚ∑•šĹúśĖĻťĚĘÁöĄŚéüŚõ†ťúÄŤ¶ĀŤß£śěź Apache Phoenix ŚļēŚĪāÁöĄŚéüŚßčśĖᚼ∂ԾƚĻüŚįĪśėĮŚ≠ėŚú® HDFS šłäÁöĄ HFile„ÄāšĹÜśėĮÁĒĪšļé Phoenix śúȍᙍļęÁöĄšłÄŚ•óśēįśćģÁľĖÁ†ĀśĖĻŚľŹÔľĆšĹÜśėĮÁĒĪšļéśú¨šļļŚĮĻ Phoenix ŤŅôŚ•óś†Ļśú¨ŚįĪšłćÁÜüśāČԾƜČÄšĽ•ŚŹ™ŤÉōᙌ∑ĪŚéĽÁúčÁõłŚÖ≥šĽ£Á†Ā„ÄāšĹÜśėĮApache Phoenix
śėĮšł™Ś§ßŚ∑•Á®čŚēäԾƚłćŚŹĮŤÉĹšłÄšł™šłÄšł™śĖᚼ∂ŚéĽśČĺÁöĄÔľĆŤŅôšľöÁõłŚĹďÁöĄśÖĘ„Äā Ść≥ŚįÜŚŹĎŚłÉÁöĄ APACHE KAFKA 2.8 ŚįÜšłćťúÄŤ¶ĀšĺĚŤĶĖ ‚ĶTRANSLATE THISPAGE
Apache Kafka ÁöĄś†łŚŅÉŤģĺŤģ°śėĮśó•ŚŅóÔľąLogԾȂÄĒ‚ÄĒ šłÄšł™ÁģÄŚćēÁöĄśēįśćģÁĽďśěĄÔľĆšĹŅÁĒ®ť°ļŚļŹśďćšĹú„ÄāšĽ•śó•ŚŅóšłļšł≠ŚŅÉÁöĄŤģĺŤģ°Śł¶śĚ•šļÜťęėśēąÁöĄÁ£ĀÁõėÁľďŚÜ≤ŚíĆCPU
ÁľďŚ≠ėšĹŅÁĒ®„ÄĀťĘĄŚŹĖ„ÄĀťõ∂śč∑ŤīĚśēįśćģšľ†ŤĺďŚíĆŤģłŚ§öŚÖ∂šĽĖŚ•ĹŚ§ĄÔľĆšĽéŤÄĆšĹŅKafka
ŤÉĹŚ§üśŹźšĺõťęėśēąÁéáŚíĆŚźěŚźźťáŹÁöĄŚäüŤÉĹ„ÄāŚĮĻšļéťā£šļõŚąöśé•Ťß¶ Kafka ÁöĄšļļśĚ•ŤĮīԾƚłĽťĘėÔľątopicԾȚĽ•ŚŹäśŹźšļ§śó•ŚŅóÁöĄ SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ ŤĶ∂Śú® Data + AI Summit 2021 šĻčŚČćÔľĆDelta Lake 1.0.0 ťáćÁ£ÖŚŹĎŚłÉԾƍŅôšł™ÁČąśú¨śėĮŚüļšļé Spark 3.1 ÁöĄÔľĆŚł¶śĚ•šļÜŤģłŚ§öśĖįÁČĻśÄß„Äāśú¨śĖáŚįÜÁĽďŚźą Michael Armbrust Ś§ßÁČõŚú® Data + AI Summit 2021 ÁöĄśľĒŤģ≤„ÄäAnnouncing Delta Lake 1.0„ÄčśĚ•šĽčÁĽć Delta Lake 1.0.0 ÁČąśú¨ÁöĄšłÄšļõťá捶ĀÁöĄśĖįÁČĻśÄß„Äā šļĒśúą ‚Äď 2021 ‚Äď ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGE ŤĶ∂Śú® Data + AI Summit 2021 šĻčŚČćÔľĆDelta Lake 1.0.0 ťáćÁ£ÖŚŹĎŚłÉԾƍŅôšł™ÁČąśú¨śėĮŚüļšļé Spark 3.1 ÁöĄÔľĆŚł¶śĚ•šļÜŤģłŚ§öśĖįÁČĻśÄß„Äāśú¨śĖáŚįÜÁĽďŚźą Michael Armbrust Ś§ßÁČõŚú® Data + AI Summit 2021 ÁöĄśľĒŤģ≤„ÄäAnnouncing Delta Lake 1.0„ÄčśĚ•šĽčÁĽć Delta Lake 1.0.0 ÁČąśú¨ÁöĄšłÄšļõťá捶ĀÁöĄśĖįÁČĻśÄß„Äā DASHBOARD - ACE ADMIN(BOOTSTRAPŚźéŚŹįÁģ°ÁźÜÁ≥ĽÁĽüś®°ÁČąACEšłčŤĹĹ) Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque commodo massa sed ipsum porttitor facilisis. HBASE ‚Äď ŤŅáŚĺÄŤģįŚŅÜ-PAGE 3TRANSLATE THIS PAGE ŤÉĆśôĮťöŹÁĚÄ Apache HBase Śú®ŚźĄšł™ťĘÜŚüüÁöĄŚĻŅś≥õŚļĒÁĒ®ÔľĆŚú® HBase ŤŅźÁĽīśąĖŚļĒÁĒ®ÁöĄŤŅáÁ®čšł≠śąĎšĽ¨ŚŹĮŤÉĹšľöťĀጹįŤŅôś†∑ÁöĄťóģťĘėÔľöŚźĆšłÄšł™HBase
ťõÜÁ姚ĹŅÁĒ®ÁöĄÁĒ®śą∑Ť∂äśĚ•Ť∂䌧öԾƚłćŚźĆÁĒ®śą∑šĻčťóīÁöĄŤĮĽŚÜôśąĖŤÄÖšłćŚźĆŤ°®ÁöĄ compaction„ÄĀregion splits śďćšĹúŚŹĮŤÉĹŚĮĻŚÖ∂šĽĖÁĒ®śą∑śąĖŤ°®šļßÁĒüšļÜŚĹĪŚďć„Äā HADOOP„ÄĀHIVEÁ≠ČšłčŤĹĹŚúįŚĚÄ Centos 7.5 YUMŚģČŤ£ÖMysql; CentOSšłčŤĹĹŚúįŚĚÄ; FedorašłčŤĹĹŚúįŚĚÄ; First Steps to Scala; GitŚģČŤ£Ö; GoogleśúÄśĖįIP; Hadoop„ÄĀHiveÁ≠ČšłčŤĹĹŚúįŚĚÄ; HTTP Content-TypeŚłłÁĒ®šłÄŤßąŤ°® APACHE HUDI CLUSTERING śēįśćģŚłÉŚĪÄŚäüŤÉĹšĽčÁĽć šłļŤÉĹŚ§üśĒĮśĆĀŚŅęťÄüśĎĄŚŹĖÁöĄŚźĆśó∂šłćŚĹĪŚďćśü•ŤĮĘśÄߍÉĹԾƜąĎšĽ¨ŚľēŚÖ•šļÜClusteringśúćŚä°śĚ•ťáćŚÜôśēįśćģšĽ•šľėŚĆĖHudiśēįśćģśĻĖśĖᚼ∂ÁöĄŚłÉŚĪÄ„Äā. ClusteringśúćŚä°ŚŹĮšĽ•Śľāś≠•śąĖŚźĆś≠•ŤŅźŤ°ĆÔľĆClusteringšľöś∑ĽŚä†šļÜšłÄÁßćśĖįÁöĄREPLACEśďćšĹúÁĪĽŚěčԾƍĮ•śďćšĹúÁĪĽŚěčŚįÜŚú®HudiŚÖÉśēįśćģśó∂ťóīŤĹīšł≠ś†áŤģįClusteringśďćšĹú„Äā. śÄĽšĹďŤÄĆŤ®ÄClustering JAVAŤé∑ŚŹĖŚ∑•Á®čŤ∑ĮŚĺĄÁöĄŚá†ÁßćśĖĻś≥ē ‚Äď Á¨¨šļĒÁßćÔľö. System.out.println ( System.getProperty ("java.class.path")); ÁĽďśěúÔľö. C:\Documents and Settings\Administrator\workspace\projectName\bin. Ťé∑ŚŹĖŚĹďŚČćŚ∑•Á®čŤ∑ĮŚĺĄ. śú¨ŚćöŚģĘśĖáÁꆝô§ÁČĻŚąęŚ£įśėéԾƌ֮ťÉ®ťÉĹśėĮŚéüŚąõÔľĀ. ŚéüŚąõśĖáÁę†ÁČąśĚÉŚĹíŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģÔľą ŤŅáŚĺÄŤģįŚŅÜ ÔľČśČÄśúČԾƜú™ÁĽŹŤģłŚŹĮšłćŚĺóŤĹ¨ŤĹĹ„Äā. śú¨śĖá DOCKER ŚÖ•ťó®śēôÁ®čÔľöšŅģśĒĻťēúŚÉŹšĽďŚļďŚúįŚĚÄ ŚįÜ MySQL ÁöĄŚÖ®ťáŹśēįśćģšĽ•ŚąÜť°ĶÁöĄŚĹĘŚľŹŚĮľŚÖ•Śąį Apache Solr šł≠ 2018-08-07; Śú®Hivešł≠šĹŅÁĒ®Avro 2014-04-08 1ŤĮĄŤģļ; śó∂ŚąĽś≥®śĄŹWordPressÁĹĎÁęôÁöĄŚģČŚÖ® 2013-04-04; Keyšłļnullśó∂KafkaŚ¶āšĹēťÄČśč©ŚąÜŚĆļ(Partition) 2016-03-30 HadoopŚÖÉśēįśćģŚźąŚĻ∂ŚľāŚłłŚŹäŤß£ŚÜ≥śĖĻś≥ē 2014-04-23 2ŤĮĄŤģļ; Apache Hadoop 3.0.0-alpha1ś≠£ŚľŹŚŹĎŚłÉŚŹäŚÖ∂śõīśĖįšĽčÁĽć 2016-09-22 Śú® DOCKER šł≠ŤŅźŤ°Ć APACHE PHOENIX ŚĻ∂ŚźĮÁĒ®ŤŅúÁ®čŤįÉŤĮē ‚ĶTRANSLATETHIS PAGE
śúÄŤŅĎÁĒĪšļéŚ∑•šĹúśĖĻťĚĘÁöĄŚéüŚõ†ťúÄŤ¶ĀŤß£śěź Apache Phoenix ŚļēŚĪāÁöĄŚéüŚßčśĖᚼ∂ԾƚĻüŚįĪśėĮŚ≠ėŚú® HDFS šłäÁöĄ HFile„ÄāšĹÜśėĮÁĒĪšļé Phoenix śúȍᙍļęÁöĄšłÄŚ•óśēįśćģÁľĖÁ†ĀśĖĻŚľŹÔľĆšĹÜśėĮÁĒĪšļéśú¨šļļŚĮĻ Phoenix ŤŅôŚ•óś†Ļśú¨ŚįĪšłćÁÜüśāČԾƜČÄšĽ•ŚŹ™ŤÉōᙌ∑ĪŚéĽÁúčÁõłŚÖ≥šĽ£Á†Ā„ÄāšĹÜśėĮApache Phoenix
śėĮšł™Ś§ßŚ∑•Á®čŚēäԾƚłćŚŹĮŤÉĹšłÄšł™šłÄšł™śĖᚼ∂ŚéĽśČĺÁöĄÔľĆŤŅôšľöÁõłŚĹďÁöĄśÖĘ„Äā Ść≥ŚįÜŚŹĎŚłÉÁöĄ APACHE KAFKA 2.8 ŚįÜšłćťúÄŤ¶ĀšĺĚŤĶĖ ‚ĶTRANSLATE THISPAGE
Apache Kafka ÁöĄś†łŚŅÉŤģĺŤģ°śėĮśó•ŚŅóÔľąLogԾȂÄĒ‚ÄĒ šłÄšł™ÁģÄŚćēÁöĄśēįśćģÁĽďśěĄÔľĆšĹŅÁĒ®ť°ļŚļŹśďćšĹú„ÄāšĽ•śó•ŚŅóšłļšł≠ŚŅÉÁöĄŤģĺŤģ°Śł¶śĚ•šļÜťęėśēąÁöĄÁ£ĀÁõėÁľďŚÜ≤ŚíĆCPU
ÁľďŚ≠ėšĹŅÁĒ®„ÄĀťĘĄŚŹĖ„ÄĀťõ∂śč∑ŤīĚśēįśćģšľ†ŤĺďŚíĆŤģłŚ§öŚÖ∂šĽĖŚ•ĹŚ§ĄÔľĆšĽéŤÄĆšĹŅKafka
ŤÉĹŚ§üśŹźšĺõťęėśēąÁéáŚíĆŚźěŚźźťáŹÁöĄŚäüŤÉĹ„ÄāŚĮĻšļéťā£šļõŚąöśé•Ťß¶ Kafka ÁöĄšļļśĚ•ŤĮīԾƚłĽťĘėÔľątopicԾȚĽ•ŚŹäśŹźšļ§śó•ŚŅóÁöĄ ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for Fashion CARE AND FEEDING OF SPARK SQL About me A software engineer making up for a lifetime of tr ying to Ô¨Āx data problems at the wrong end of the pipeline. Working in the AI Group @ Bloomberg since April 2020.UI ELEMENTS
UI Elements Common UI Features & Elements. UI Elements. Raw denim you probably haven't heard of them jean shorts Austin. Food truck fixie locavore, accusamus mcsweeney's marfa nulla single-origin coffee squid. Etsy mixtape wayfarers, ethical wes anderson tofu before they sold out mcsweeney's organic lomo retro fanny pack lo-fi farm-to-table ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄ ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄÔľö śõīśĖįśó∂ťóīÔľö2015ŚĻī4śúą11śó• 11:05:06 ŚļŹŚŹ∑ ŚúįŚĚÄ ÁęĮŚŹ£ ŚõĹŚģ∂ ÁĪĽŚěč(ŚĆŅŚźćŚļ¶) Áä∂śÄĀ ŚÖ®śĶč 1 152.26.69.36 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 2 152.26.69.37 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 3 152.26.69.35 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤śĶčŤĮē 4
ŤŅáŚĺÄŤģįŚŅÜ
ŤŅáŚĺÄŤģįŚŅÜ
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: QUICKSTART Sample Project in Scala. Linking with Flink. IDE Setup. Scala REPL. ŚÖ≥ŤĀĒŚŹĮťÄČś®°ŚĚó. Running Flink on Windows. Building Flink from Source. Application Development. Basic API Concepts. APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: FLINKML Ś¶āśěúšĹ†śÉ≥Áõīśé•ŚģěŤ∑Ķ, šĹ†ŚŹĮťúÄŤ¶Ā ŚąõŚĽļšłÄšł™FlinkÁ®čŚļŹ . ÁĄ∂ŚźéŚźéԾƌú®šĹ†ť°ĻÁõģÁöĄ pom.xml šł≠Śä†ŚÖ•FlinkMLÁöĄšĺĚŤĶĖ„Äā. org.apache.flink flink-ml_2.10 1.3-SNAPSHOT . ťúÄŤ¶Āś≥®śĄŹÁöĄśėĮFlinkMLÁõģŚČćś≤°śúČÁľĖŤĮĎŤŅõšļĆŤŅõŚą∂śĖᚼ∂ÁČą„Äā.ÁāĻŚáĽ
APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ ŚįÜśēįśćģŚä†ŤĹĹŚąį CARBONDATA Ť°®šł≠. ŤŅôšł™ŚĎĹšĽ§ÁĒ®šļéŚä†ŤĹĹ csv ś†ľŚľŹÁöĄśĖᚼ∂Śąį carbondata Ť°®šł≠, OPTIONS ŚŹāśēįŚú®Śä†ŤĹĹśēįśćģÁöĄŤŅáÁ®čšł≠śėĮŚŹĮťÄČÁöĄ„Äā. Śú® OPTIONS šł≠śąĎšĽ¨ŚŹĮšĽ•śĆáŚģöšĽĽšĹēÁöĄŚÖąŚÜ≥śĚ°šĽ∂ԾƜĮĒŚ¶āÔľöDELIMITER, QUOTECHAR, FILEHEADER, ESCAPECHAR, MULTILINE„Äā. LOAD DATA INPATH 'folder_path' INTO ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for Fashion CARE AND FEEDING OF SPARK SQL About me A software engineer making up for a lifetime of tr ying to Ô¨Āx data problems at the wrong end of the pipeline. Working in the AI Group @ Bloomberg since April 2020.UI ELEMENTS
UI Elements Common UI Features & Elements. UI Elements. Raw denim you probably haven't heard of them jean shorts Austin. Food truck fixie locavore, accusamus mcsweeney's marfa nulla single-origin coffee squid. Etsy mixtape wayfarers, ethical wes anderson tofu before they sold out mcsweeney's organic lomo retro fanny pack lo-fi farm-to-table ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄ ÁĺéŚõĹšĽ£ÁźÜśúćŚä°Śô®ŚúįŚĚÄÔľö śõīśĖįśó∂ťóīÔľö2015ŚĻī4śúą11śó• 11:05:06 ŚļŹŚŹ∑ ŚúįŚĚÄ ÁęĮŚŹ£ ŚõĹŚģ∂ ÁĪĽŚěč(ŚĆŅŚźćŚļ¶) Áä∂śÄĀ ŚÖ®śĶč 1 152.26.69.36 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 2 152.26.69.37 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤ śĶčŤĮē 3 152.26.69.35 8080 ÁĺéŚõĹ ÁĺéŚõĹ anonymous Á©ļťó≤śĶčŤĮē 4
ŤŅáŚĺÄŤģįŚŅÜ
ŤŅáŚĺÄŤģįŚŅÜ
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: QUICKSTART Sample Project in Scala. Linking with Flink. IDE Setup. Scala REPL. ŚÖ≥ŤĀĒŚŹĮťÄČś®°ŚĚó. Running Flink on Windows. Building Flink from Source. Application Development. Basic API Concepts. APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: FLINKML Ś¶āśěúšĹ†śÉ≥Áõīśé•ŚģěŤ∑Ķ, šĹ†ŚŹĮťúÄŤ¶Ā ŚąõŚĽļšłÄšł™FlinkÁ®čŚļŹ . ÁĄ∂ŚźéŚźéԾƌú®šĹ†ť°ĻÁõģÁöĄ pom.xml šł≠Śä†ŚÖ•FlinkMLÁöĄšĺĚŤĶĖ„Äā. org.apache.flink flink-ml_2.10 1.3-SNAPSHOT . ťúÄŤ¶Āś≥®śĄŹÁöĄśėĮFlinkMLÁõģŚČćś≤°śúČÁľĖŤĮĎŤŅõšļĆŤŅõŚą∂śĖᚼ∂ÁČą„Äā.ÁāĻŚáĽ
APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ ŚįÜśēįśćģŚä†ŤĹĹŚąį CARBONDATA Ť°®šł≠. ŤŅôšł™ŚĎĹšĽ§ÁĒ®šļéŚä†ŤĹĹ csv ś†ľŚľŹÁöĄśĖᚼ∂Śąį carbondata Ť°®šł≠, OPTIONS ŚŹāśēįŚú®Śä†ŤĹĹśēįśćģÁöĄŤŅáÁ®čšł≠śėĮŚŹĮťÄČÁöĄ„Äā. Śú® OPTIONS šł≠śąĎšĽ¨ŚŹĮšĽ•śĆáŚģöšĽĽšĹēÁöĄŚÖąŚÜ≥śĚ°šĽ∂ԾƜĮĒŚ¶āÔľöDELIMITER, QUOTECHAR, FILEHEADER, ESCAPECHAR, MULTILINE„Äā. LOAD DATA INPATH 'folder_path' INTOŤŅáŚĺÄŤģįŚŅÜ
ŤŅáŚĺÄŤģįŚŅÜ
DASHBOARD - ACE ADMIN(BOOTSTRAPŚźéŚŹįÁģ°ÁźÜÁ≥ĽÁĽüś®°ÁČąACEšłčŤĹĹ) Dashboard - Ace Admin (BootstrapŚźéŚŹįÁģ°ÁźÜÁ≥ĽÁĽüś®°ÁČąAcešłčŤĹĹ) śéߌą∂ŚŹį. UI & ÁĽĄšĽ∂. Layouts. Top Menu. Two Menus 1. Two Menus 2. Default Mobile Menu. Mobile Menu 2.WWW.ITEBLOG.COM
www.iteblog.com
CARE AND FEEDING OF SPARK SQL About me A software engineer making up for a lifetime of tr ying to Ô¨Āx data problems at the wrong end of the pipeline. Working in the AI Group @ Bloomberg since April 2020. APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: BATCH EXAMPLES The algorithm works in two steps: First, the texts are splits the text to individual words. Second, the words are grouped and counted. The WordCount example implements the above described algorithm with input parameters: --input --output . As test data, any text file will do. ŤŅáŚĺÄŤģįŚŅÜ-PAGE 45 śú¨śĖášĹúŤÄÖÔľöśĚéŚĮÖŚ®ĀԾƚĽéšļ茧ߜēįśćģ„ÄĀśúļŚô®Ś≠¶šĻ†śĖĻťĚĘÁöĄŚ∑•šĹúÔľĆÁõģŚČćŚįĪŤĀĆšļéCVTEŤĀĒÁ≥ĽśĖĻŚľŹÔľöŚĺģšŅ°ÔľącoridcÔľČԾƝāģÁģĪÔľą251469031@qq.comԾȌéüśĖáťďĺśé•Ôľö Spark2.1.0 + CarbonData1.0.0ťõÜÁ姜®°ŚľŹťÉ®ÁĹ≤ŚŹäšĹŅÁĒ®ŚÖ•ťó®1 ŚľēŤ®ÄApache
CarbonDataśėĮšłÄšł™ťĚĘŚźĎŚ§ßśēįśćģŚĻ≥ŚŹįÁöĄŚüļšļéÁīĘŚľēÁöĄŚąóŚľŹśēįśćģś†ľŚľŹÔľĆÁĒĪŚćéšłļŚ§ßśēįśćģŚõĘťėüŤī°ÁĆģÁĽôApacheÁ§ĺŚĆļÔľĆÁõģŚČćśúÄśĖįÁČąśú¨ ŤŅáŚĺÄŤģįŚŅÜ-PAGE 68 śú¨śĖáŚįÜšĽčÁĽćŚ¶āšĹēťÄöŤŅáÁģÄŚćēŚúįŚá†ś≠•śĚ•ŚľÄŚßčÁľĖŚÜôšĹ†ÁöĄ Flink Java Á®čŚļŹ„ÄāŤ¶ĀśĪā ÁľĖŚÜôšĹ†ÁöĄFlink JavaÁ®čŚļŹŚĒĮšłÄÁöĄŤ¶ĀśĪāśėĮťúÄŤ¶ĀŚģČŤ£ÖMaven 3.0.4(śąĖŤÄÖśõīťęė)ŚíĆJava 7.x(śąĖŤÄÖśõīťęė) ŚąõŚĽļFlink JavaŚ∑•Á®čšĹŅÁĒ®šłčťĚĘŚÖ∂šł≠šłÄšł™ŚĎĹšĽ§śĚ•ŚąõŚĽļFlink JavaŚ∑•Á®č1„ÄĀšĹŅÁĒ®Maven archetypesÔľö$ mvn archetype:generate \ ŤŅáŚĺÄŤģįŚŅÜ-PAGE 43 Áü•ŚźćÁöĄŚ§ßśēįśćģśäÄśúĮśě∂śěĄšłéŚļĒÁĒ®ŚąÜšļęśäÄśúĮŚćöŚģĘԾƌąÜšļęŚĆ֜訚ĹÜšłćťôźšļé Hadoop„ÄĀSpark„ÄĀKafka„ÄĀHudi„ÄĀIceberg„ÄĀDelta Lake Á≠ČŚ§ßśēįśćģÁõłŚÖ≥ÁöĄśäÄśúĮ„Äā ŤŅáŚĺÄŤģįŚŅÜ-PAGE 40 śąĎšĽ¨ťÉĹÁü•ťĀďÔľĆÁõģŚČć Apache Beam šĽÖšĽÖśŹźšĺõšļÜ Java ŚíĆ Python šł§ÁßćŤĮ≠Ť®ÄÁöĄ APIԾƌįöšłćśĒĮśĆĀ Scala ÁõłŚÖ≥ÁöĄ API„ÄāŚüļšļéś≠§ŚÖ®ÁźÉśúÄŚ§ßÁöĄśĶĀťü≥šĻźśúćŚä°ŚēÜ Spotify ŚľÄŚŹĎšļÜ Scio ԾƌÖ∂šłļ Apache Beam ŚíĆ Google Cloud Dataflow śŹźšĺõšļÜScala APIԾƚĹŅŚĺóśąĎšĽ¨ŚŹĮšĽ•Áõīśé•šĹŅÁĒ® Scala śĚ•ÁľĖŚÜô BeamŚļĒÁĒ®Á®čŚļŹ„Äā
ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for Fashion DASHBOARD - ACE ADMIN(BOOTSTRAPŚźéŚŹįÁģ°ÁźÜÁ≥ĽÁĽüś®°ÁČąACEšłčŤĹĹ) Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque commodo massa sed ipsum porttitor facilisis.UI ELEMENTS
UI Elements Common UI Features & Elements. UI Elements. Raw denim you probably haven't heard of them jean shorts Austin. Food truck fixie locavore, accusamus mcsweeney's marfa nulla single-origin coffee squid. Etsy mixtape wayfarers, ethical wes anderson tofu before they sold out mcsweeney's organic lomo retro fanny pack lo-fi farm-to-table SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ Apache Spark 3.0 śėĮŚ¶āšĹēśŹźťęė SQL Ś∑•šĹúŤīüŤĹĹÁöĄśÄߍÉĹ. Śú®Śá†šĻéśČÄśúČŚ§ĄÁźÜŚ§ćśĚāśēįśćģÁöĄťĘÜŚüüÔľĆSpark Ś∑≤ÁĽŹŤŅÖťÄüśąźšłļśēįśćģŚíĆŚąÜśěźÁĒüŚĎĹŚĎ®śúüŚõĘťėüÁöĄšļčŚģěšłäÁöĄŚąÜŚłÉŚľŹŤģ°Áģóś°Üśě∂„Äā.Spark 3.0
śúÄŚŹóśúüŚĺÖÁöĄÁČĻśÄßšĻ蚳ĜėĮśĖįÁöĄŤá™ťÄāŚļĒśü•ŤĮĘśČߍ°Ćś°Üśě∂ (Adaptive Query ExecutionÔľĆAQE)ԾƍĮ•ś°Üśě∂Ťß£ŚÜ≥šļÜŤģłŚ§ö Spark SQL HBASE ‚Äď ŤŅáŚĺÄŤģįŚŅÜ-PAGE 3TRANSLATE THIS PAGE ŤÉĆśôĮťöŹÁĚÄ Apache HBase Śú®ŚźĄšł™ťĘÜŚüüÁöĄŚĻŅś≥õŚļĒÁĒ®ÔľĆŚú® HBase ŤŅźÁĽīśąĖŚļĒÁĒ®ÁöĄŤŅáÁ®čšł≠śąĎšĽ¨ŚŹĮŤÉĹšľöťĀጹįŤŅôś†∑ÁöĄťóģťĘėÔľöŚźĆšłÄšł™HBase
ťõÜÁ姚ĹŅÁĒ®ÁöĄÁĒ®śą∑Ť∂äśĚ•Ť∂䌧öԾƚłćŚźĆÁĒ®śą∑šĻčťóīÁöĄŤĮĽŚÜôśąĖŤÄÖšłćŚźĆŤ°®ÁöĄ compaction„ÄĀregion splits śďćšĹúŚŹĮŤÉĹŚĮĻŚÖ∂šĽĖÁĒ®śą∑śąĖŤ°®šļßÁĒüšļÜŚĹĪŚďć„Äā APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
JAVAŤé∑ŚŹĖŚ∑•Á®čŤ∑ĮŚĺĄÁöĄŚá†ÁßćśĖĻś≥ē ‚Äď Á¨¨šļĒÁßćÔľö. System.out.println ( System.getProperty ("java.class.path")); ÁĽďśěúÔľö. C:\Documents and Settings\Administrator\workspace\projectName\bin. Ťé∑ŚŹĖŚĹďŚČćŚ∑•Á®čŤ∑ĮŚĺĄ. śú¨ŚćöŚģĘśĖáÁꆝô§ÁČĻŚąęŚ£įśėéԾƌ֮ťÉ®ťÉĹśėĮŚéüŚąõÔľĀ. ŚéüŚąõśĖáÁę†ÁČąśĚÉŚĹíŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģÔľą ŤŅáŚĺÄŤģįŚŅÜ ÔľČśČÄśúČԾƜú™ÁĽŹŤģłŚŹĮšłćŚĺóŤĹ¨ŤĹĹ„Äā. śú¨śĖá APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: QUICKSTART Sample Project in Scala. Linking with Flink. IDE Setup. Scala REPL. ŚÖ≥ŤĀĒŚŹĮťÄČś®°ŚĚó. Running Flink on Windows. Building Flink from Source. Application Development. Basic API Concepts. APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: FLINKML Ś¶āśěúšĹ†śÉ≥Áõīśé•ŚģěŤ∑Ķ, šĹ†ŚŹĮťúÄŤ¶Ā ŚąõŚĽļšłÄšł™FlinkÁ®čŚļŹ . ÁĄ∂ŚźéŚźéԾƌú®šĹ†ť°ĻÁõģÁöĄ pom.xml šł≠Śä†ŚÖ•FlinkMLÁöĄšĺĚŤĶĖ„Äā. org.apache.flink flink-ml_2.10 1.3-SNAPSHOT . ťúÄŤ¶Āś≥®śĄŹÁöĄśėĮFlinkMLÁõģŚČćś≤°śúČÁľĖŤĮĎŤŅõšļĆŤŅõŚą∂śĖᚼ∂ÁČą„Äā.ÁāĻŚáĽ
ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for Fashion DASHBOARD - ACE ADMIN(BOOTSTRAPŚźéŚŹįÁģ°ÁźÜÁ≥ĽÁĽüś®°ÁČąACEšłčŤĹĹ) Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque commodo massa sed ipsum porttitor facilisis.UI ELEMENTS
UI Elements Common UI Features & Elements. UI Elements. Raw denim you probably haven't heard of them jean shorts Austin. Food truck fixie locavore, accusamus mcsweeney's marfa nulla single-origin coffee squid. Etsy mixtape wayfarers, ethical wes anderson tofu before they sold out mcsweeney's organic lomo retro fanny pack lo-fi farm-to-table SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ Apache Spark 3.0 śėĮŚ¶āšĹēśŹźťęė SQL Ś∑•šĹúŤīüŤĹĹÁöĄśÄߍÉĹ. Śú®Śá†šĻéśČÄśúČŚ§ĄÁźÜŚ§ćśĚāśēįśćģÁöĄťĘÜŚüüÔľĆSpark Ś∑≤ÁĽŹŤŅÖťÄüśąźšłļśēįśćģŚíĆŚąÜśěźÁĒüŚĎĹŚĎ®śúüŚõĘťėüÁöĄšļčŚģěšłäÁöĄŚąÜŚłÉŚľŹŤģ°Áģóś°Üśě∂„Äā.Spark 3.0
śúÄŚŹóśúüŚĺÖÁöĄÁČĻśÄßšĻ蚳ĜėĮśĖįÁöĄŤá™ťÄāŚļĒśü•ŤĮĘśČߍ°Ćś°Üśě∂ (Adaptive Query ExecutionÔľĆAQE)ԾƍĮ•ś°Üśě∂Ťß£ŚÜ≥šļÜŤģłŚ§ö Spark SQL HBASE ‚Äď ŤŅáŚĺÄŤģįŚŅÜ-PAGE 3TRANSLATE THIS PAGE ŤÉĆśôĮťöŹÁĚÄ Apache HBase Śú®ŚźĄšł™ťĘÜŚüüÁöĄŚĻŅś≥õŚļĒÁĒ®ÔľĆŚú® HBase ŤŅźÁĽīśąĖŚļĒÁĒ®ÁöĄŤŅáÁ®čšł≠śąĎšĽ¨ŚŹĮŤÉĹšľöťĀጹįŤŅôś†∑ÁöĄťóģťĘėÔľöŚźĆšłÄšł™HBase
ťõÜÁ姚ĹŅÁĒ®ÁöĄÁĒ®śą∑Ť∂äśĚ•Ť∂䌧öԾƚłćŚźĆÁĒ®śą∑šĻčťóīÁöĄŤĮĽŚÜôśąĖŤÄÖšłćŚźĆŤ°®ÁöĄ compaction„ÄĀregion splits śďćšĹúŚŹĮŤÉĹŚĮĻŚÖ∂šĽĖÁĒ®śą∑śąĖŤ°®šļßÁĒüšļÜŚĹĪŚďć„Äā APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
JAVAŤé∑ŚŹĖŚ∑•Á®čŤ∑ĮŚĺĄÁöĄŚá†ÁßćśĖĻś≥ē ‚Äď Á¨¨šļĒÁßćÔľö. System.out.println ( System.getProperty ("java.class.path")); ÁĽďśěúÔľö. C:\Documents and Settings\Administrator\workspace\projectName\bin. Ťé∑ŚŹĖŚĹďŚČćŚ∑•Á®čŤ∑ĮŚĺĄ. śú¨ŚćöŚģĘśĖáÁꆝô§ÁČĻŚąęŚ£įśėéԾƌ֮ťÉ®ťÉĹśėĮŚéüŚąõÔľĀ. ŚéüŚąõśĖáÁę†ÁČąśĚÉŚĹíŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģÔľą ŤŅáŚĺÄŤģįŚŅÜ ÔľČśČÄśúČԾƜú™ÁĽŹŤģłŚŹĮšłćŚĺóŤĹ¨ŤĹĹ„Äā. śú¨śĖá APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: QUICKSTART Sample Project in Scala. Linking with Flink. IDE Setup. Scala REPL. ŚÖ≥ŤĀĒŚŹĮťÄČś®°ŚĚó. Running Flink on Windows. Building Flink from Source. Application Development. Basic API Concepts. APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: FLINKML Ś¶āśěúšĹ†śÉ≥Áõīśé•ŚģěŤ∑Ķ, šĹ†ŚŹĮťúÄŤ¶Ā ŚąõŚĽļšłÄšł™FlinkÁ®čŚļŹ . ÁĄ∂ŚźéŚźéԾƌú®šĹ†ť°ĻÁõģÁöĄ pom.xml šł≠Śä†ŚÖ•FlinkMLÁöĄšĺĚŤĶĖ„Äā. org.apache.flink flink-ml_2.10 1.3-SNAPSHOT . ťúÄŤ¶Āś≥®śĄŹÁöĄśėĮFlinkMLÁõģŚČćś≤°śúČÁľĖŤĮĎŤŅõšļĆŤŅõŚą∂śĖᚼ∂ÁČą„Äā.ÁāĻŚáĽ
SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ ŤĶ∂Śú® Data + AI Summit 2021 šĻčŚČćÔľĆDelta Lake 1.0.0 ťáćÁ£ÖŚŹĎŚłÉԾƍŅôšł™ÁČąśú¨śėĮŚüļšļé Spark 3.1 ÁöĄÔľĆŚł¶śĚ•šļÜŤģłŚ§öśĖįÁČĻśÄß„Äāśú¨śĖáŚįÜÁĽďŚźą Michael Armbrust Ś§ßÁČõŚú® Data + AI Summit 2021 ÁöĄśľĒŤģ≤„ÄäAnnouncing Delta Lake 1.0„ÄčśĚ•šĽčÁĽć Delta Lake 1.0.0 ÁČąśú¨ÁöĄšłÄšļõťá捶ĀÁöĄśĖįÁČĻśÄß„Äā APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: EXAMPLES Examples; Examples. Sample Project in Java and Sample Project in Scala are guides to setting up Maven and SBT projects and include simple implementations of a word count application.. Monitoring Wikipedia Edits is a more complete example of a streaming analytics application.. Building real-time dashboard applications with Apache Flink, Elasticsearch, and Kibana is a blog post at elastic.co LEARNING SPARKŚģĆśēīÁČąšłčŤĹĹLearning
SparkŤŅôśú¨šĻ¶ťďĺśé•śėĮŚģĆśēīÁȹԾƌíĆšĻčŚČćÁöĄťĘĄŤßąÁČąśėĮšłćšłÄś†∑ÁöĄÔľĆśąĎšłćśėĮś†áťĘėŚÖö„ÄāŤŅôťáĆśŹźšĺõÁöĄLearning SparkÁĒĶŚ≠źšĻ¶ś†ľŚľŹśėĮmobi„ÄĀpdfšĽ•ŚŹäepubšłČÁß朆ľŚľŹÁöĄśĖᚼ∂Ծƌ¶āśěúšĹ†śúČšļöť©¨ťÄäKindleÁĒĶŚ≠źšĻ¶ťėÖŤĮĽŚô®ÔľĆśėĮŚŹĮšĽ•Áõīśé•ťėÖŤĮĽmobi„ÄĀpdf„ÄāšĹÜŚ¶āśěúšĹ†ÁĒ®ÁĒĶŤĄĎԾƚĻüŚŹĮšĽ•šłčŤĹĹÁõłŚļĒÁöĄPCÁČąťėÖŤĮĽŚô®„Äā
Ś§ßśēįśćģŚíĆŚąÜŚłÉŚľŹÁĽŹŚÖłŤģļśĖáśĪáśÄĽ šłčťĚĘŤģļśĖáŚĚášłļŚ§ßśēįśćģŚíĆŚąÜŚłÉŚľŹśĮĒŤĺÉÁĽŹŚÖłÁöĄŤģļśĖáԾƌĆÖśč¨ÔľöCAP„ÄĀBASE„ÄĀ2PC„ÄĀšłÄŤáīśÄߌ揍ģģ„ÄĀšłÄŤáīśÄߌ﹌łĆ„ÄĀťÄĽŤĺĎśó∂ťíü„ÄĀLeases Á≠Č„ÄāŚ¶āśěúŚ§ßŚģ∂ŤŅėśúČśĮĒŤĺÉŚ•ĹÁöĄŤģļśĖáԾƜ¨ĘŤŅéŚú®šłčťĚĘŤĮĄŤģļ„Äā ŚąÜŚłÉŚľŹÁźÜŤģļ Time, Clocks, and the Ordering of Events in a Distributed System Reaching Agreement in the Presence of DOCKER ŚÖ•ťó®śēôÁ®čÔľöšŅģśĒĻťēúŚÉŹšĽďŚļďŚúįŚĚÄ ŚįÜ MySQL ÁöĄŚÖ®ťáŹśēįśćģšĽ•ŚąÜť°ĶÁöĄŚĹĘŚľŹŚĮľŚÖ•Śąį Apache Solr šł≠ 2018-08-07; Śú®Hivešł≠šĹŅÁĒ®Avro 2014-04-08 1ŤĮĄŤģļ; śó∂ŚąĽś≥®śĄŹWordPressÁĹĎÁęôÁöĄŚģČŚÖ® 2013-04-04; Keyšłļnullśó∂KafkaŚ¶āšĹēťÄČśč©ŚąÜŚĆļ(Partition) 2016-03-30 HadoopŚÖÉśēįśćģŚźąŚĻ∂ŚľāŚłłŚŹäŤß£ŚÜ≥śĖĻś≥ē 2014-04-23 2ŤĮĄŤģļ; Apache Hadoop 3.0.0-alpha1ś≠£ŚľŹŚŹĎŚłÉŚŹäŚÖ∂śõīśĖįšĽčÁĽć 2016-09-22 Śú®ÁļŅś≠£Śú®Ť°®Ťĺ匾ŹŚ≠¶šĻ†„ÄĀśĶčŤĮē RegExr is an online tool to learn, build, & test Regular Expressions(RegEx / RegExp).
ŤŅáŚĺÄŤģįŚŅÜ
ŤŅáŚĺÄŤģįŚŅÜ
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: BATCH EXAMPLES The algorithm works in two steps: First, the texts are splits the text to individual words. Second, the words are grouped and counted. The WordCount example implements the above described algorithm with input parameters: --input --output . As test data, any text file will do. HADOOP2.X ś∑ĪŚÖ•śĶÖŚáļšľĀšłöÁļߌļĒÁĒ®ŚģěśąėŤßÜťĘĎšłčŤĹĹ śú¨ŚćöŚģĘŚąÜšļęÁöĄŚÖ∂šĽĖŤßÜťĘĎšłčŤĹĹŚúįŚĚÄÔľö„Ääšľ†śôļśí≠ŚģĘHadoopŚģěśąėŤßÜťĘĎšłčŤĹĹŚúįŚĚÄ„Äč„ÄĀ„Ääšľ†śôļśí≠ŚģĘHadoopŤĮĺÁ®čŤßÜťĘĎŤĶĄśĖô„Äč„ÄĀ„ÄäHadoopŚÖ•ťó®ŤßÜťĘĎŚąÜšļę„Äč„ÄĀ„ÄäHadoopŚ§ßśēįśćģťõ∂ŚüļÁ°ÄŚģěśąėŚüĻŤģ≠śēôÁ®čšłčŤĹĹ„Äč„ÄĀ„ÄäHadoop2.x
ś∑ĪŚÖ•śĶÖŚáļšľĀšłöÁļߌļĒÁĒ®ŚģěśąėŤßÜťĘĎšłčŤĹĹ„Äč„ÄĀ„ÄäHadoopśĖįśČčŚÖ•ťó®ŤßÜťĘĎÁôĺŚļ¶ÁĹĎÁõėšłčŤĹĹ„Äčśú¨ŚćöŚģĘ
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: COMPONENT STACK Internals; Component Stack; Component Stack. As a software stack, Flink is a layered system. The different layers of the stack build on top of each other and raise the abstraction level of the program representations they accept: ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for Fashion DASHBOARD - ACE ADMIN(BOOTSTRAPŚźéŚŹįÁģ°ÁźÜÁ≥ĽÁĽüś®°ÁČąACEšłčŤĹĹ) Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque commodo massa sed ipsum porttitor facilisis.UI ELEMENTS
UI Elements Common UI Features & Elements. UI Elements. Raw denim you probably haven't heard of them jean shorts Austin. Food truck fixie locavore, accusamus mcsweeney's marfa nulla single-origin coffee squid. Etsy mixtape wayfarers, ethical wes anderson tofu before they sold out mcsweeney's organic lomo retro fanny pack lo-fi farm-to-table SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ Apache Spark 3.0 śėĮŚ¶āšĹēśŹźťęė SQL Ś∑•šĹúŤīüŤĹĹÁöĄśÄߍÉĹ. Śú®Śá†šĻéśČÄśúČŚ§ĄÁźÜŚ§ćśĚāśēįśćģÁöĄťĘÜŚüüÔľĆSpark Ś∑≤ÁĽŹŤŅÖťÄüśąźšłļśēįśćģŚíĆŚąÜśěźÁĒüŚĎĹŚĎ®śúüŚõĘťėüÁöĄšļčŚģěšłäÁöĄŚąÜŚłÉŚľŹŤģ°Áģóś°Üśě∂„Äā.Spark 3.0
śúÄŚŹóśúüŚĺÖÁöĄÁČĻśÄßšĻ蚳ĜėĮśĖįÁöĄŤá™ťÄāŚļĒśü•ŤĮĘśČߍ°Ćś°Üśě∂ (Adaptive Query ExecutionÔľĆAQE)ԾƍĮ•ś°Üśě∂Ťß£ŚÜ≥šļÜŤģłŚ§ö Spark SQL HBASE ‚Äď ŤŅáŚĺÄŤģįŚŅÜ-PAGE 3TRANSLATE THIS PAGE ŤÉĆśôĮťöŹÁĚÄ Apache HBase Śú®ŚźĄšł™ťĘÜŚüüÁöĄŚĻŅś≥õŚļĒÁĒ®ÔľĆŚú® HBase ŤŅźÁĽīśąĖŚļĒÁĒ®ÁöĄŤŅáÁ®čšł≠śąĎšĽ¨ŚŹĮŤÉĹšľöťĀጹįŤŅôś†∑ÁöĄťóģťĘėÔľöŚźĆšłÄšł™HBase
ťõÜÁ姚ĹŅÁĒ®ÁöĄÁĒ®śą∑Ť∂äśĚ•Ť∂䌧öԾƚłćŚźĆÁĒ®śą∑šĻčťóīÁöĄŤĮĽŚÜôśąĖŤÄÖšłćŚźĆŤ°®ÁöĄ compaction„ÄĀregion splits śďćšĹúŚŹĮŤÉĹŚĮĻŚÖ∂šĽĖÁĒ®śą∑śąĖŤ°®šļßÁĒüšļÜŚĹĪŚďć„Äā APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
JAVAŤé∑ŚŹĖŚ∑•Á®čŤ∑ĮŚĺĄÁöĄŚá†ÁßćśĖĻś≥ē ‚Äď Á¨¨šļĒÁßćÔľö. System.out.println ( System.getProperty ("java.class.path")); ÁĽďśěúÔľö. C:\Documents and Settings\Administrator\workspace\projectName\bin. Ťé∑ŚŹĖŚĹďŚČćŚ∑•Á®čŤ∑ĮŚĺĄ. śú¨ŚćöŚģĘśĖáÁꆝô§ÁČĻŚąęŚ£įśėéԾƌ֮ťÉ®ťÉĹśėĮŚéüŚąõÔľĀ. ŚéüŚąõśĖáÁę†ÁČąśĚÉŚĹíŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģÔľą ŤŅáŚĺÄŤģįŚŅÜ ÔľČśČÄśúČԾƜú™ÁĽŹŤģłŚŹĮšłćŚĺóŤĹ¨ŤĹĹ„Äā. śú¨śĖá APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: QUICKSTART Sample Project in Scala. Linking with Flink. IDE Setup. Scala REPL. ŚÖ≥ŤĀĒŚŹĮťÄČś®°ŚĚó. Running Flink on Windows. Building Flink from Source. Application Development. Basic API Concepts. APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: FLINKML Ś¶āśěúšĹ†śÉ≥Áõīśé•ŚģěŤ∑Ķ, šĹ†ŚŹĮťúÄŤ¶Ā ŚąõŚĽļšłÄšł™FlinkÁ®čŚļŹ . ÁĄ∂ŚźéŚźéԾƌú®šĹ†ť°ĻÁõģÁöĄ pom.xml šł≠Śä†ŚÖ•FlinkMLÁöĄšĺĚŤĶĖ„Äā. org.apache.flink flink-ml_2.10 1.3-SNAPSHOT . ťúÄŤ¶Āś≥®śĄŹÁöĄśėĮFlinkMLÁõģŚČćś≤°śúČÁľĖŤĮĎŤŅõšļĆŤŅõŚą∂śĖᚼ∂ÁČą„Äā.ÁāĻŚáĽ
ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for Fashion DASHBOARD - ACE ADMIN(BOOTSTRAPŚźéŚŹįÁģ°ÁźÜÁ≥ĽÁĽüś®°ÁČąACEšłčŤĹĹ) Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque commodo massa sed ipsum porttitor facilisis.UI ELEMENTS
UI Elements Common UI Features & Elements. UI Elements. Raw denim you probably haven't heard of them jean shorts Austin. Food truck fixie locavore, accusamus mcsweeney's marfa nulla single-origin coffee squid. Etsy mixtape wayfarers, ethical wes anderson tofu before they sold out mcsweeney's organic lomo retro fanny pack lo-fi farm-to-table SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ Apache Spark 3.0 śėĮŚ¶āšĹēśŹźťęė SQL Ś∑•šĹúŤīüŤĹĹÁöĄśÄߍÉĹ. Śú®Śá†šĻéśČÄśúČŚ§ĄÁźÜŚ§ćśĚāśēįśćģÁöĄťĘÜŚüüÔľĆSpark Ś∑≤ÁĽŹŤŅÖťÄüśąźšłļśēįśćģŚíĆŚąÜśěźÁĒüŚĎĹŚĎ®śúüŚõĘťėüÁöĄšļčŚģěšłäÁöĄŚąÜŚłÉŚľŹŤģ°Áģóś°Üśě∂„Äā.Spark 3.0
śúÄŚŹóśúüŚĺÖÁöĄÁČĻśÄßšĻ蚳ĜėĮśĖįÁöĄŤá™ťÄāŚļĒśü•ŤĮĘśČߍ°Ćś°Üśě∂ (Adaptive Query ExecutionÔľĆAQE)ԾƍĮ•ś°Üśě∂Ťß£ŚÜ≥šļÜŤģłŚ§ö Spark SQL HBASE ‚Äď ŤŅáŚĺÄŤģįŚŅÜ-PAGE 3TRANSLATE THIS PAGE ŤÉĆśôĮťöŹÁĚÄ Apache HBase Śú®ŚźĄšł™ťĘÜŚüüÁöĄŚĻŅś≥õŚļĒÁĒ®ÔľĆŚú® HBase ŤŅźÁĽīśąĖŚļĒÁĒ®ÁöĄŤŅáÁ®čšł≠śąĎšĽ¨ŚŹĮŤÉĹšľöťĀጹįŤŅôś†∑ÁöĄťóģťĘėÔľöŚźĆšłÄšł™HBase
ťõÜÁ姚ĹŅÁĒ®ÁöĄÁĒ®śą∑Ť∂äśĚ•Ť∂䌧öԾƚłćŚźĆÁĒ®śą∑šĻčťóīÁöĄŤĮĽŚÜôśąĖŤÄÖšłćŚźĆŤ°®ÁöĄ compaction„ÄĀregion splits śďćšĹúŚŹĮŤÉĹŚĮĻŚÖ∂šĽĖÁĒ®śą∑śąĖŤ°®šļßÁĒüšļÜŚĹĪŚďć„Äā APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
JAVAŤé∑ŚŹĖŚ∑•Á®čŤ∑ĮŚĺĄÁöĄŚá†ÁßćśĖĻś≥ē ‚Äď Á¨¨šļĒÁßćÔľö. System.out.println ( System.getProperty ("java.class.path")); ÁĽďśěúÔľö. C:\Documents and Settings\Administrator\workspace\projectName\bin. Ťé∑ŚŹĖŚĹďŚČćŚ∑•Á®čŤ∑ĮŚĺĄ. śú¨ŚćöŚģĘśĖáÁꆝô§ÁČĻŚąęŚ£įśėéԾƌ֮ťÉ®ťÉĹśėĮŚéüŚąõÔľĀ. ŚéüŚąõśĖáÁę†ÁČąśĚÉŚĹíŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģÔľą ŤŅáŚĺÄŤģįŚŅÜ ÔľČśČÄśúČԾƜú™ÁĽŹŤģłŚŹĮšłćŚĺóŤĹ¨ŤĹĹ„Äā. śú¨śĖá APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: QUICKSTART Sample Project in Scala. Linking with Flink. IDE Setup. Scala REPL. ŚÖ≥ŤĀĒŚŹĮťÄČś®°ŚĚó. Running Flink on Windows. Building Flink from Source. Application Development. Basic API Concepts. APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: FLINKML Ś¶āśěúšĹ†śÉ≥Áõīśé•ŚģěŤ∑Ķ, šĹ†ŚŹĮťúÄŤ¶Ā ŚąõŚĽļšłÄšł™FlinkÁ®čŚļŹ . ÁĄ∂ŚźéŚźéԾƌú®šĹ†ť°ĻÁõģÁöĄ pom.xml šł≠Śä†ŚÖ•FlinkMLÁöĄšĺĚŤĶĖ„Äā. org.apache.flink flink-ml_2.10 1.3-SNAPSHOT . ťúÄŤ¶Āś≥®śĄŹÁöĄśėĮFlinkMLÁõģŚČćś≤°śúČÁľĖŤĮĎŤŅõšļĆŤŅõŚą∂śĖᚼ∂ÁČą„Äā.ÁāĻŚáĽ
SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ ŤĶ∂Śú® Data + AI Summit 2021 šĻčŚČćÔľĆDelta Lake 1.0.0 ťáćÁ£ÖŚŹĎŚłÉԾƍŅôšł™ÁČąśú¨śėĮŚüļšļé Spark 3.1 ÁöĄÔľĆŚł¶śĚ•šļÜŤģłŚ§öśĖįÁČĻśÄß„Äāśú¨śĖáŚįÜÁĽďŚźą Michael Armbrust Ś§ßÁČõŚú® Data + AI Summit 2021 ÁöĄśľĒŤģ≤„ÄäAnnouncing Delta Lake 1.0„ÄčśĚ•šĽčÁĽć Delta Lake 1.0.0 ÁČąśú¨ÁöĄšłÄšļõťá捶ĀÁöĄśĖįÁČĻśÄß„Äā APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: EXAMPLES Examples; Examples. Sample Project in Java and Sample Project in Scala are guides to setting up Maven and SBT projects and include simple implementations of a word count application.. Monitoring Wikipedia Edits is a more complete example of a streaming analytics application.. Building real-time dashboard applications with Apache Flink, Elasticsearch, and Kibana is a blog post at elastic.co LEARNING SPARKŚģĆśēīÁČąšłčŤĹĹLearning
SparkŤŅôśú¨šĻ¶ťďĺśé•śėĮŚģĆśēīÁȹԾƌíĆšĻčŚČćÁöĄťĘĄŤßąÁČąśėĮšłćšłÄś†∑ÁöĄÔľĆśąĎšłćśėĮś†áťĘėŚÖö„ÄāŤŅôťáĆśŹźšĺõÁöĄLearning SparkÁĒĶŚ≠źšĻ¶ś†ľŚľŹśėĮmobi„ÄĀpdfšĽ•ŚŹäepubšłČÁß朆ľŚľŹÁöĄśĖᚼ∂Ծƌ¶āśěúšĹ†śúČšļöť©¨ťÄäKindleÁĒĶŚ≠źšĻ¶ťėÖŤĮĽŚô®ÔľĆśėĮŚŹĮšĽ•Áõīśé•ťėÖŤĮĽmobi„ÄĀpdf„ÄāšĹÜŚ¶āśěúšĹ†ÁĒ®ÁĒĶŤĄĎԾƚĻüŚŹĮšĽ•šłčŤĹĹÁõłŚļĒÁöĄPCÁČąťėÖŤĮĽŚô®„Äā
Ś§ßśēįśćģŚíĆŚąÜŚłÉŚľŹÁĽŹŚÖłŤģļśĖáśĪáśÄĽ šłčťĚĘŤģļśĖáŚĚášłļŚ§ßśēįśćģŚíĆŚąÜŚłÉŚľŹśĮĒŤĺÉÁĽŹŚÖłÁöĄŤģļśĖáԾƌĆÖśč¨ÔľöCAP„ÄĀBASE„ÄĀ2PC„ÄĀšłÄŤáīśÄߌ揍ģģ„ÄĀšłÄŤáīśÄߌ﹌łĆ„ÄĀťÄĽŤĺĎśó∂ťíü„ÄĀLeases Á≠Č„ÄāŚ¶āśěúŚ§ßŚģ∂ŤŅėśúČśĮĒŤĺÉŚ•ĹÁöĄŤģļśĖáԾƜ¨ĘŤŅéŚú®šłčťĚĘŤĮĄŤģļ„Äā ŚąÜŚłÉŚľŹÁźÜŤģļ Time, Clocks, and the Ordering of Events in a Distributed System Reaching Agreement in the Presence of DOCKER ŚÖ•ťó®śēôÁ®čÔľöšŅģśĒĻťēúŚÉŹšĽďŚļďŚúįŚĚÄ ŚįÜ MySQL ÁöĄŚÖ®ťáŹśēįśćģšĽ•ŚąÜť°ĶÁöĄŚĹĘŚľŹŚĮľŚÖ•Śąį Apache Solr šł≠ 2018-08-07; Śú®Hivešł≠šĹŅÁĒ®Avro 2014-04-08 1ŤĮĄŤģļ; śó∂ŚąĽś≥®śĄŹWordPressÁĹĎÁęôÁöĄŚģČŚÖ® 2013-04-04; Keyšłļnullśó∂KafkaŚ¶āšĹēťÄČśč©ŚąÜŚĆļ(Partition) 2016-03-30 HadoopŚÖÉśēįśćģŚźąŚĻ∂ŚľāŚłłŚŹäŤß£ŚÜ≥śĖĻś≥ē 2014-04-23 2ŤĮĄŤģļ; Apache Hadoop 3.0.0-alpha1ś≠£ŚľŹŚŹĎŚłÉŚŹäŚÖ∂śõīśĖįšĽčÁĽć 2016-09-22 Śú®ÁļŅś≠£Śú®Ť°®Ťĺ匾ŹŚ≠¶šĻ†„ÄĀśĶčŤĮē RegExr is an online tool to learn, build, & test Regular Expressions(RegEx / RegExp).
ŤŅáŚĺÄŤģįŚŅÜ
ŤŅáŚĺÄŤģįŚŅÜ
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: BATCH EXAMPLES The algorithm works in two steps: First, the texts are splits the text to individual words. Second, the words are grouped and counted. The WordCount example implements the above described algorithm with input parameters: --input --output . As test data, any text file will do. HADOOP2.X ś∑ĪŚÖ•śĶÖŚáļšľĀšłöÁļߌļĒÁĒ®ŚģěśąėŤßÜťĘĎšłčŤĹĹ śú¨ŚćöŚģĘŚąÜšļęÁöĄŚÖ∂šĽĖŤßÜťĘĎšłčŤĹĹŚúįŚĚÄÔľö„Ääšľ†śôļśí≠ŚģĘHadoopŚģěśąėŤßÜťĘĎšłčŤĹĹŚúįŚĚÄ„Äč„ÄĀ„Ääšľ†śôļśí≠ŚģĘHadoopŤĮĺÁ®čŤßÜťĘĎŤĶĄśĖô„Äč„ÄĀ„ÄäHadoopŚÖ•ťó®ŤßÜťĘĎŚąÜšļę„Äč„ÄĀ„ÄäHadoopŚ§ßśēįśćģťõ∂ŚüļÁ°ÄŚģěśąėŚüĻŤģ≠śēôÁ®čšłčŤĹĹ„Äč„ÄĀ„ÄäHadoop2.x
ś∑ĪŚÖ•śĶÖŚáļšľĀšłöÁļߌļĒÁĒ®ŚģěśąėŤßÜťĘĎšłčŤĹĹ„Äč„ÄĀ„ÄäHadoopśĖįśČčŚÖ•ťó®ŤßÜťĘĎÁôĺŚļ¶ÁĹĎÁõėšłčŤĹĹ„Äčśú¨ŚćöŚģĘ
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: COMPONENT STACK Internals; Component Stack; Component Stack. As a software stack, Flink is a layered system. The different layers of the stack build on top of each other and raise the abstraction level of the program representations they accept: ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for Fashion DASHBOARD - ACE ADMIN(BOOTSTRAPŚźéŚŹįÁģ°ÁźÜÁ≥ĽÁĽüś®°ÁČąACEšłčŤĹĹ) Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque commodo massa sed ipsum porttitor facilisis.UI ELEMENTS
UI Elements Common UI Features & Elements. UI Elements. Raw denim you probably haven't heard of them jean shorts Austin. Food truck fixie locavore, accusamus mcsweeney's marfa nulla single-origin coffee squid. Etsy mixtape wayfarers, ethical wes anderson tofu before they sold out mcsweeney's organic lomo retro fanny pack lo-fi farm-to-table SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ Apache Spark 3.0 śėĮŚ¶āšĹēśŹźťęė SQL Ś∑•šĹúŤīüŤĹĹÁöĄśÄߍÉĹ. Śú®Śá†šĻéśČÄśúČŚ§ĄÁźÜŚ§ćśĚāśēįśćģÁöĄťĘÜŚüüÔľĆSpark Ś∑≤ÁĽŹŤŅÖťÄüśąźšłļśēįśćģŚíĆŚąÜśěźÁĒüŚĎĹŚĎ®śúüŚõĘťėüÁöĄšļčŚģěšłäÁöĄŚąÜŚłÉŚľŹŤģ°Áģóś°Üśě∂„Äā.Spark 3.0
śúÄŚŹóśúüŚĺÖÁöĄÁČĻśÄßšĻ蚳ĜėĮśĖįÁöĄŤá™ťÄāŚļĒśü•ŤĮĘśČߍ°Ćś°Üśě∂ (Adaptive Query ExecutionÔľĆAQE)ԾƍĮ•ś°Üśě∂Ťß£ŚÜ≥šļÜŤģłŚ§ö Spark SQL HBASE ‚Äď ŤŅáŚĺÄŤģįŚŅÜ-PAGE 3TRANSLATE THIS PAGE ŤÉĆśôĮťöŹÁĚÄ Apache HBase Śú®ŚźĄšł™ťĘÜŚüüÁöĄŚĻŅś≥õŚļĒÁĒ®ÔľĆŚú® HBase ŤŅźÁĽīśąĖŚļĒÁĒ®ÁöĄŤŅáÁ®čšł≠śąĎšĽ¨ŚŹĮŤÉĹšľöťĀጹįŤŅôś†∑ÁöĄťóģťĘėÔľöŚźĆšłÄšł™HBase
ťõÜÁ姚ĹŅÁĒ®ÁöĄÁĒ®śą∑Ť∂äśĚ•Ť∂䌧öԾƚłćŚźĆÁĒ®śą∑šĻčťóīÁöĄŤĮĽŚÜôśąĖŤÄÖšłćŚźĆŤ°®ÁöĄ compaction„ÄĀregion splits śďćšĹúŚŹĮŤÉĹŚĮĻŚÖ∂šĽĖÁĒ®śą∑śąĖŤ°®šļßÁĒüšļÜŚĹĪŚďć„Äā APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
JAVAŤé∑ŚŹĖŚ∑•Á®čŤ∑ĮŚĺĄÁöĄŚá†ÁßćśĖĻś≥ē ‚Äď Á¨¨šļĒÁßćÔľö. System.out.println ( System.getProperty ("java.class.path")); ÁĽďśěúÔľö. C:\Documents and Settings\Administrator\workspace\projectName\bin. Ťé∑ŚŹĖŚĹďŚČćŚ∑•Á®čŤ∑ĮŚĺĄ. śú¨ŚćöŚģĘśĖáÁꆝô§ÁČĻŚąęŚ£įśėéԾƌ֮ťÉ®ťÉĹśėĮŚéüŚąõÔľĀ. ŚéüŚąõśĖáÁę†ÁČąśĚÉŚĹíŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģÔľą ŤŅáŚĺÄŤģįŚŅÜ ÔľČśČÄśúČԾƜú™ÁĽŹŤģłŚŹĮšłćŚĺóŤĹ¨ŤĹĹ„Äā. śú¨śĖá APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: QUICKSTART Sample Project in Scala. Linking with Flink. IDE Setup. Scala REPL. ŚÖ≥ŤĀĒŚŹĮťÄČś®°ŚĚó. Running Flink on Windows. Building Flink from Source. Application Development. Basic API Concepts. APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: FLINKML Ś¶āśěúšĹ†śÉ≥Áõīśé•ŚģěŤ∑Ķ, šĹ†ŚŹĮťúÄŤ¶Ā ŚąõŚĽļšłÄšł™FlinkÁ®čŚļŹ . ÁĄ∂ŚźéŚźéԾƌú®šĹ†ť°ĻÁõģÁöĄ pom.xml šł≠Śä†ŚÖ•FlinkMLÁöĄšĺĚŤĶĖ„Äā. org.apache.flink flink-ml_2.10 1.3-SNAPSHOT . ťúÄŤ¶Āś≥®śĄŹÁöĄśėĮFlinkMLÁõģŚČćś≤°śúČÁľĖŤĮĎŤŅõšļĆŤŅõŚą∂śĖᚼ∂ÁČą„Äā.ÁāĻŚáĽ
ITEBLOG - ŤŅáŚĺÄŤģįŚŅÜTRANSLATE THIS PAGESPARKCASSANDRAFLINKHADOOPHBASEFLUME śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč. Apache Kafka śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„Äā. Kafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„Äā. Śú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂ DATA MESH IN PRACTICE GOES BEYOND THE DATA LAKE ONLINE Data Mesh in Practice Max Schultze - max.schultze@zalando.de Arif Wider - awider@thoughtworks.com 17-11-2020 How Europe‚Äôs Leading Online Platform for Fashion DASHBOARD - ACE ADMIN(BOOTSTRAPŚźéŚŹįÁģ°ÁźÜÁ≥ĽÁĽüś®°ÁČąACEšłčŤĹĹ) Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque commodo massa sed ipsum porttitor facilisis.UI ELEMENTS
UI Elements Common UI Features & Elements. UI Elements. Raw denim you probably haven't heard of them jean shorts Austin. Food truck fixie locavore, accusamus mcsweeney's marfa nulla single-origin coffee squid. Etsy mixtape wayfarers, ethical wes anderson tofu before they sold out mcsweeney's organic lomo retro fanny pack lo-fi farm-to-table SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ Apache Spark 3.0 śėĮŚ¶āšĹēśŹźťęė SQL Ś∑•šĹúŤīüŤĹĹÁöĄśÄߍÉĹ. Śú®Śá†šĻéśČÄśúČŚ§ĄÁźÜŚ§ćśĚāśēįśćģÁöĄťĘÜŚüüÔľĆSpark Ś∑≤ÁĽŹŤŅÖťÄüśąźšłļśēįśćģŚíĆŚąÜśěźÁĒüŚĎĹŚĎ®śúüŚõĘťėüÁöĄšļčŚģěšłäÁöĄŚąÜŚłÉŚľŹŤģ°Áģóś°Üśě∂„Äā.Spark 3.0
śúÄŚŹóśúüŚĺÖÁöĄÁČĻśÄßšĻ蚳ĜėĮśĖįÁöĄŤá™ťÄāŚļĒśü•ŤĮĘśČߍ°Ćś°Üśě∂ (Adaptive Query ExecutionÔľĆAQE)ԾƍĮ•ś°Üśě∂Ťß£ŚÜ≥šļÜŤģłŚ§ö Spark SQL HBASE ‚Äď ŤŅáŚĺÄŤģįŚŅÜ-PAGE 3TRANSLATE THIS PAGE ŤÉĆśôĮťöŹÁĚÄ Apache HBase Śú®ŚźĄšł™ťĘÜŚüüÁöĄŚĻŅś≥õŚļĒÁĒ®ÔľĆŚú® HBase ŤŅźÁĽīśąĖŚļĒÁĒ®ÁöĄŤŅáÁ®čšł≠śąĎšĽ¨ŚŹĮŤÉĹšľöťĀጹįŤŅôś†∑ÁöĄťóģťĘėÔľöŚźĆšłÄšł™HBase
ťõÜÁ姚ĹŅÁĒ®ÁöĄÁĒ®śą∑Ť∂äśĚ•Ť∂䌧öԾƚłćŚźĆÁĒ®śą∑šĻčťóīÁöĄŤĮĽŚÜôśąĖŤÄÖšłćŚźĆŤ°®ÁöĄ compaction„ÄĀregion splits śďćšĹúŚŹĮŤÉĹŚĮĻŚÖ∂šĽĖÁĒ®śą∑śąĖŤ°®šļßÁĒüšļÜŚĹĪŚďć„Äā APACHE CARBONDATA 1.4.0 šł≠śĖáśĖáś°£ Apache CarbonData 1.4.0 šł≠śĖáśĖáś°£. ś¨ĘŤŅéśĚ•Śąį Apache CarbonData„Äā. Apache CarbonData śėĮšłÄÁßćśĖįÁöĄŤě挟ąŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆŚą©ÁĒ®ŚÖąŤŅõÁöĄŚąóŚľŹŚ≠ėŚā®ÔľĆÁīĘŚľēԾƌéčÁľ©ŚíĆÁľĖÁ†ĀśäÄśúĮśŹźťęėŤģ°ÁģóśēąÁéáԾƚĽéŤÄƌ䆌Ņęśü•ŤĮĘťÄüŚļ¶ÔľĆŚÖ∂śü•ŤĮĘťÄüŚļ¶śĮĒ PetaBytes śēįśćģŚŅꚳĚł™śēįťáŹÁļß„Äā. śú¨ÁĒ®śą∑śĆáŚć󜏟šĺõšļÜśúČŚÖ≥CarbonData
JAVAŤé∑ŚŹĖŚ∑•Á®čŤ∑ĮŚĺĄÁöĄŚá†ÁßćśĖĻś≥ē ‚Äď Á¨¨šļĒÁßćÔľö. System.out.println ( System.getProperty ("java.class.path")); ÁĽďśěúÔľö. C:\Documents and Settings\Administrator\workspace\projectName\bin. Ťé∑ŚŹĖŚĹďŚČćŚ∑•Á®čŤ∑ĮŚĺĄ. śú¨ŚćöŚģĘśĖáÁꆝô§ÁČĻŚąęŚ£įśėéԾƌ֮ťÉ®ťÉĹśėĮŚéüŚąõÔľĀ. ŚéüŚąõśĖáÁę†ÁČąśĚÉŚĹíŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģÔľą ŤŅáŚĺÄŤģįŚŅÜ ÔľČśČÄśúČԾƜú™ÁĽŹŤģłŚŹĮšłćŚĺóŤĹ¨ŤĹĹ„Äā. śú¨śĖá APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: QUICKSTART Sample Project in Scala. Linking with Flink. IDE Setup. Scala REPL. ŚÖ≥ŤĀĒŚŹĮťÄČś®°ŚĚó. Running Flink on Windows. Building Flink from Source. Application Development. Basic API Concepts. APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: FLINKML Ś¶āśěúšĹ†śÉ≥Áõīśé•ŚģěŤ∑Ķ, šĹ†ŚŹĮťúÄŤ¶Ā ŚąõŚĽļšłÄšł™FlinkÁ®čŚļŹ . ÁĄ∂ŚźéŚźéԾƌú®šĹ†ť°ĻÁõģÁöĄ pom.xml šł≠Śä†ŚÖ•FlinkMLÁöĄšĺĚŤĶĖ„Äā. org.apache.flink flink-ml_2.10 1.3-SNAPSHOT . ťúÄŤ¶Āś≥®śĄŹÁöĄśėĮFlinkMLÁõģŚČćś≤°śúČÁľĖŤĮĎŤŅõšļĆŤŅõŚą∂śĖᚼ∂ÁČą„Äā.ÁāĻŚáĽ
SPARK ‚Äď ŤŅáŚĺÄŤģįŚŅÜ ŤĶ∂Śú® Data + AI Summit 2021 šĻčŚČćÔľĆDelta Lake 1.0.0 ťáćÁ£ÖŚŹĎŚłÉԾƍŅôšł™ÁČąśú¨śėĮŚüļšļé Spark 3.1 ÁöĄÔľĆŚł¶śĚ•šļÜŤģłŚ§öśĖįÁČĻśÄß„Äāśú¨śĖáŚįÜÁĽďŚźą Michael Armbrust Ś§ßÁČõŚú® Data + AI Summit 2021 ÁöĄśľĒŤģ≤„ÄäAnnouncing Delta Lake 1.0„ÄčśĚ•šĽčÁĽć Delta Lake 1.0.0 ÁČąśú¨ÁöĄšłÄšļõťá捶ĀÁöĄśĖįÁČĻśÄß„Äā APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: EXAMPLES Examples; Examples. Sample Project in Java and Sample Project in Scala are guides to setting up Maven and SBT projects and include simple implementations of a word count application.. Monitoring Wikipedia Edits is a more complete example of a streaming analytics application.. Building real-time dashboard applications with Apache Flink, Elasticsearch, and Kibana is a blog post at elastic.co LEARNING SPARKŚģĆśēīÁČąšłčŤĹĹLearning
SparkŤŅôśú¨šĻ¶ťďĺśé•śėĮŚģĆśēīÁȹԾƌíĆšĻčŚČćÁöĄťĘĄŤßąÁČąśėĮšłćšłÄś†∑ÁöĄÔľĆśąĎšłćśėĮś†áťĘėŚÖö„ÄāŤŅôťáĆśŹźšĺõÁöĄLearning SparkÁĒĶŚ≠źšĻ¶ś†ľŚľŹśėĮmobi„ÄĀpdfšĽ•ŚŹäepubšłČÁß朆ľŚľŹÁöĄśĖᚼ∂Ծƌ¶āśěúšĹ†śúČšļöť©¨ťÄäKindleÁĒĶŚ≠źšĻ¶ťėÖŤĮĽŚô®ÔľĆśėĮŚŹĮšĽ•Áõīśé•ťėÖŤĮĽmobi„ÄĀpdf„ÄāšĹÜŚ¶āśěúšĹ†ÁĒ®ÁĒĶŤĄĎԾƚĻüŚŹĮšĽ•šłčŤĹĹÁõłŚļĒÁöĄPCÁČąťėÖŤĮĽŚô®„Äā
Ś§ßśēįśćģŚíĆŚąÜŚłÉŚľŹÁĽŹŚÖłŤģļśĖáśĪáśÄĽ šłčťĚĘŤģļśĖáŚĚášłļŚ§ßśēįśćģŚíĆŚąÜŚłÉŚľŹśĮĒŤĺÉÁĽŹŚÖłÁöĄŤģļśĖáԾƌĆÖśč¨ÔľöCAP„ÄĀBASE„ÄĀ2PC„ÄĀšłÄŤáīśÄߌ揍ģģ„ÄĀšłÄŤáīśÄߌ﹌łĆ„ÄĀťÄĽŤĺĎśó∂ťíü„ÄĀLeases Á≠Č„ÄāŚ¶āśěúŚ§ßŚģ∂ŤŅėśúČśĮĒŤĺÉŚ•ĹÁöĄŤģļśĖáԾƜ¨ĘŤŅéŚú®šłčťĚĘŤĮĄŤģļ„Äā ŚąÜŚłÉŚľŹÁźÜŤģļ Time, Clocks, and the Ordering of Events in a Distributed System Reaching Agreement in the Presence of DOCKER ŚÖ•ťó®śēôÁ®čÔľöšŅģśĒĻťēúŚÉŹšĽďŚļďŚúįŚĚÄ ŚįÜ MySQL ÁöĄŚÖ®ťáŹśēįśćģšĽ•ŚąÜť°ĶÁöĄŚĹĘŚľŹŚĮľŚÖ•Śąį Apache Solr šł≠ 2018-08-07; Śú®Hivešł≠šĹŅÁĒ®Avro 2014-04-08 1ŤĮĄŤģļ; śó∂ŚąĽś≥®śĄŹWordPressÁĹĎÁęôÁöĄŚģČŚÖ® 2013-04-04; Keyšłļnullśó∂KafkaŚ¶āšĹēťÄČśč©ŚąÜŚĆļ(Partition) 2016-03-30 HadoopŚÖÉśēįśćģŚźąŚĻ∂ŚľāŚłłŚŹäŤß£ŚÜ≥śĖĻś≥ē 2014-04-23 2ŤĮĄŤģļ; Apache Hadoop 3.0.0-alpha1ś≠£ŚľŹŚŹĎŚłÉŚŹäŚÖ∂śõīśĖįšĽčÁĽć 2016-09-22 Śú®ÁļŅś≠£Śú®Ť°®Ťĺ匾ŹŚ≠¶šĻ†„ÄĀśĶčŤĮē RegExr is an online tool to learn, build, & test Regular Expressions(RegEx / RegExp).
ŤŅáŚĺÄŤģįŚŅÜ
ŤŅáŚĺÄŤģįŚŅÜ
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: BATCH EXAMPLES The algorithm works in two steps: First, the texts are splits the text to individual words. Second, the words are grouped and counted. The WordCount example implements the above described algorithm with input parameters: --input --output . As test data, any text file will do. HADOOP2.X ś∑ĪŚÖ•śĶÖŚáļšľĀšłöÁļߌļĒÁĒ®ŚģěśąėŤßÜťĘĎšłčŤĹĹ śú¨ŚćöŚģĘŚąÜšļęÁöĄŚÖ∂šĽĖŤßÜťĘĎšłčŤĹĹŚúįŚĚÄÔľö„Ääšľ†śôļśí≠ŚģĘHadoopŚģěśąėŤßÜťĘĎšłčŤĹĹŚúįŚĚÄ„Äč„ÄĀ„Ääšľ†śôļśí≠ŚģĘHadoopŤĮĺÁ®čŤßÜťĘĎŤĶĄśĖô„Äč„ÄĀ„ÄäHadoopŚÖ•ťó®ŤßÜťĘĎŚąÜšļę„Äč„ÄĀ„ÄäHadoopŚ§ßśēįśćģťõ∂ŚüļÁ°ÄŚģěśąėŚüĻŤģ≠śēôÁ®čšłčŤĹĹ„Äč„ÄĀ„ÄäHadoop2.x
ś∑ĪŚÖ•śĶÖŚáļšľĀšłöÁļߌļĒÁĒ®ŚģěśąėŤßÜťĘĎšłčŤĹĹ„Äč„ÄĀ„ÄäHadoopśĖįśČčŚÖ•ťó®ŤßÜťĘĎÁôĺŚļ¶ÁĹĎÁõėšłčŤĹĹ„Äčśú¨ŚćöŚģĘ
APACHE FLINK 1.3-SNAPSHOT šł≠śĖáśĖáś°£: COMPONENT STACK Internals; Component Stack; Component Stack. As a software stack, Flink is a layered system. The different layers of the stack build on top of each other and raise the abstraction level of the program representations they accept:* ť¶Ėť°Ķ
* Spark
* Cassandra
* Flink
* Hadoop
* HBase
* Flume
* Kafka
* Scala
* ŤĶĄśĖôŚąÜšļę
* ŚłłÁĒ®Ś∑•ŚÖ∑
* iteblog_hadoopŚÖ¨šľóŚŹ∑śČÄśúČŤĶĄśĖôŚąóŤ°® * Jsonś†ľŚľŹŚĆĖŚ∑•ŚÖ∑ * Śú®ÁļŅś≠£ŚąôŤ°®Ťĺ匾ŹśĶčŤĮē * HTTP Content-TypeŚłłÁĒ®šłÄŤßąŤ°® * Á®čŚļŹŚĎėŚõĺšĻ¶śé®Ťćź* RGBťĘúŤČ≤ŚŹāŤÄÉ
* Raft ŚćŹŤģģŚŹĮŤßÜŚĆĖšĽčÁĽć * ŚĺģšŅ°ŚÖ¨šľóŚŹ∑ Markdown ÁľĖŤĺĎŚô®* EmojišĽ£Á†ĀŚ§ßŚÖ®
* ŚÖ≥šļé
* śĒĮšĽėŚģĚŤĶěŚä©
* ŚĻŅŚĎ䌟ąšĹú
* ŚŹčťďĺÁĒ≥ŤĮ∑
* šłļšĽÄšĻąšłćŤÉĹŚ§ćŚą∂* ÁĹĎÁęôŚúįŚõĺ
* ŚĺģšŅ°ŚįŹÁ®čŚļŹ
* šłļšĽÄšĻąśú¨ŚćöŚģĘśó†ś≥ēŤĮĄŤģļŚíĆÁôĽŚĹē * Centos 7.5 YUMŚģČŤ£ÖMysql__
ŤŅáŚĺÄŤģįŚŅÜ
šłďś≥®šļ錧ߜēįśćģśäÄśúĮśěĄśě∂ŚŹäŚļĒÁĒ®ÔľĆŚĺģšŅ°ŚÖ¨šľóŚŹ∑:ŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģ__ __
__
__
ÁôĽŚĹē
__
ś¨ĘŤŅéŚÖ≥ś≥®Ś§ßśēįśćģśäÄśúĮśě∂śěĄšłéś°ąšĺčŚĺģšŅ°ŚÖ¨šľóŚŹ∑ÔľöŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģ„Äā__
ś¨ĘŤŅéŚÖ≥ś≥®ŚĺģšŅ°ŚÖ¨šľóŚŹ∑Ôľö ŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģ*
*
*
*
*
*
*
*
*
*
*
*
Apache Iceberg šĽ£Á†ĀŤįÉŤĮēśäÄŚ∑ßśúÄÁÉ≠śé퍰Ɯ¶ú
*
śĶŹŤßą (132894)__199ŚĖúś¨Ę 1HiveśēįśćģÁĪĽŚěčŤĹ¨śćĘ*
śĶŹŤßą (103555)__67ŚĖúś¨Ę 2HiveŚłłÁĒ®Ś≠óÁ¨¶šł≤ŚáĹśēį*
śĶŹŤßą (95034)__57ŚĖúś¨Ę 3Hive insert intoŤĮ≠ŚŹ•ÁĒ®ś≥ē*
śĶŹŤßą (89923)__65ŚĖúś¨Ę 4Apache Spark SQLŤá™ťÄāŚļĒśČߍ°ĆŚģěŤ∑Ķ*
śĶŹŤßą (89361)__119ŚĖúś¨Ę 5HiveŚá†ÁßćśēįśćģŚĮľŚÖ•śĖĻŚľŹ*
śĶŹŤßą (86379)__292ŚĖúś¨Ę 6Á≤ĺŚŅÉśĒ∂ťõÜÁöĄHadoopŚ≠¶šĻ†ŤĶĄśĖô(śĆĀÁĽ≠śõīśĖį)*
śĶŹŤßą (82883)__64ŚĖúś¨Ę 7šĹŅÁĒ®HttpClientťÄöŤŅápostśĖĻŚľŹŚŹĎťÄĀjsonśēįśćģ*
śĶŹŤßą (80895)__84ŚĖúś¨Ę 8Spark: sortByŚíĆsortByKeyŚáĹśēįŤĮ¶Ťß£*
śĶŹŤßą (78850)__67ŚĖúś¨Ę 9Hive:ORC File FormatŚ≠ėŚā®ś†ľŚľŹŤĮ¶Ťß£*
śĶŹŤßą (76556)__156ŚĖúś¨Ę 10SparkŚŅęťÄüŚÖ•ťó®śĆáŚćó(Quick Start Spark)Presto__
PRESTO Śä®śÄĀŤŅ᜼§ÔľąDYNAMIC FILTERINGԾȌéüÁźÜšłéŚļĒÁĒ® śó©Śú®2005ŚĻīÔľĆOracle śēįśćģŚļďŚįĪśĒĮśĆĀśĮĒŤĺÉšłįŚĮĆÁöĄ dynamic filtering ŚäüŤÉĹԾƍÄĆ SparkŚíĆ Presto
Śú®śúÄŤŅĎÁČąśú¨śČ挾ČßčśĒĮśĆĀŤŅôšł™ŚäüŤÉĹ„Äāśú¨śĖáŚįÜšĽčÁĽć Presto Śä®śÄĀŤŅ᜼§ÁöĄŚéüÁźÜšĽ•ŚŹäŚÖ∑šĹďšĹŅÁĒ®„ÄāApache Spark ÁöĄŚä®śÄĀŚąÜŚĆļŤ£ĀŚáŹApache Spark 3.0 ÁĽôśąĎšĽ¨Śł¶śĚ•šļÜŤģłŚ§öÁöĄśĖįÁČĻśÄßÁĒ®šļéŚä†ťÄüśü•ŤĮĘśÄߍÉĹԾƌÖ∂šł≠šłÄšł™ŚįĪśėĮŚä®śÄĀŚąÜŚĆļŤ£ĀŚáŹÔľąDynamic Partition PruningÔľĆDPPÔľČԾƜČÄŤįďÁöĄŚä®śÄĀŚąÜŚĆļŤ£ĀŚČ™ŚįĪ__ w397090770 __
4Ś§©ŚČć __ 52‚ĄÉ __ 0ŤĮĄŤģļ__1ŚĖúś¨Ę
Delta Lake__
DELTA LAKE 1.0.0 ŚŹĎŚłÉԾƌ§öť°ĻśĖįÁČĻśÄßťáćÁ£ÖŚŹĎŚłÉ ŤĶ∂Śú® Data + AI Summit 2021 šĻčŚČćÔľĆDelta Lake 1.0.0 ťáćÁ£ÖŚŹĎŚłÉԾƍŅôšł™ÁČąśú¨śėĮŚüļšļé Spark 3.1 ÁöĄÔľĆŚł¶śĚ•šļÜŤģłŚ§öśĖįÁČĻśÄß„Äāśú¨śĖáŚįÜÁĽďŚźą Michael Armbrust Ś§ßÁČõŚú® Data + AI Summit 2021 ÁöĄśľĒŤģ≤„ÄäAnnouncing Delta Lake 1.0„ÄčśĚ•šĽčÁĽć Delta Lake 1.0.0 ÁČąśú¨ÁöĄšłÄšļõťá捶ĀÁöĄśĖįÁČĻśÄß„ÄāŚ¶āśěúśÉ≥ŚŹäśó∂šļÜŤß£Spark„ÄĀHadoopśąĖŤÄÖHBaseÁõłŚÖ≥ÁöĄśĖáÁę†ÔľĆś¨ĘŤŅéŚÖ≥ś≥®ŚĺģšŅ°ŚÖ¨šľóŚŹ∑ÔľöŤŅáŚĺÄŤģįŚŅÜŚ§ßśēįśćģDeltaLake 0.1
__ w397090770 __
1ŚĎ®ŚČć (05-27) __ 141‚ĄÉ __ 0ŤĮĄŤģļ__0ŚĖúś¨Ę
Delta Lake__
DELTA LAKE: THE DEFINITIVE GUIDE ťĘĄŤßąÁČąšłčŤĹĹ śú¨šĻ¶šĹúŤÄÖ Denny Lee, Tathagata Das, Vini JaiswalԾƝʥŤģ°2022ŚĻī4śúąŚáļÁȹԾƌáļÁČąÁ§ĺO'Reilly Media,
Inc.ÔľĆISBNÔľö9781098104528ŚąÜśěźŚíĆśúļŚô®Ś≠¶šĻ†ś®°ŚěčÁöĄŚ•ĹŚĚŹŚŹĖŚÜ≥šļéŚģÉšĽ¨śČÄšĺĚŤĶĖÁöĄśēįśćģ„Äāśü•ŤĮĘŚ§ĄÁźÜŤŅáÁöĄśēįśćģŚĻ∂šĽéšł≠Ťé∑ŚĺóŤßĀŤß£ťúÄŤ¶ĀšłÄšł™ŚĀ•Ś£ģÁöĄśēįśćģÁģ°ťĀď‚ÄĒ‚ÄĒšĽ•ŚŹäšłÄšł™śúČśēąÁöĄŚ≠ėŚā®Ťß£ŚÜ≥śĖĻś°ąÔľĆšĽ•Á°ģšŅĚśēįśćģŤī®ťáŹ„ÄĀśēįśćģŚģĆśēīśÄߌíĆśÄߍÉĹ„Äāśú¨śĆáŚćóŚźĎśā®šĽčÁĽć Delta LakeԾƍŅôśėĮšłÄÁß挾Ä__ w397090770 __
1ŚĎ®ŚČć (05-27) __ 68‚ĄÉ __ 0ŤĮĄŤģļ__1ŚĖúś¨Ę
Delta Lake__
DATA LAKEHOUSE ÁöĄśľĒŚŹė śú¨śĖáśėĮ Forest Rim Technology śēįśćģŚõĘťėüśíįŚÜôÁöĄÔľĆšĹúŤÄÖ Bill Inmon ŚíĆ Mary LevinsԾƌÖ∂šł≠ Bill Inmon ŤĘęÁßįšłļśėĮśēįśćģšĽďŚļďšĻčÁą∂ԾƜúÄśó©ÁöĄśēįśćģšĽďŚļāŚŅĶśŹźŚáļŤÄÖԾƍĘę„ÄäŤģ°ÁģóśúļšłĖÁēĆ„ÄčŤĮĄšłļŤģ°ÁģóśúļŤ°ĆšłöŚéÜŚŹ≤šłäśúÄŚÖ∑ŚĹĪŚďćŚäõÁöĄŚćĀŚ§ßšļļÁČ©šĻ蚳ĄÄāŚéüŚßčśēįśćģÁöĄśĆĎśąėťöŹÁĚÄŚ§ßťáŹŚļĒÁĒ®Á®čŚļŹÁöĄŚáļÁéįԾƚļßÁĒüšļÜÁõłŚźĆÁöĄśēįśćģŚú®šłćŚźĆŚúįśĖĻŚáļÁéįšłćŚźĆŚÄľÁöĄśÉÖŚÜĶ„ÄāšłļšļÜŚĀöŚáļŚÜ≥ŚģöÔľĆÁĒ®śą∑ŚŅÖť°ĽśČĺ__ w397090770 __
2ŚĎ®ŚČć (05-25) __ 92‚ĄÉ __ 0ŤĮĄŤģļ__0ŚĖúś¨Ę
Spark__
APACHE SPARK 3.0 śėĮŚ¶āšĹēśŹźťęė SQL Ś∑•šĹúŤīüŤĹĹÁöĄśÄߍÉĹ Śú®Śá†šĻéśČÄśúČŚ§ĄÁźÜŚ§ćśĚāśēįśćģÁöĄťĘÜŚüüÔľĆSpark Ś∑≤ÁĽŹŤŅÖťÄüśąźšłļśēįśćģŚíĆŚąÜśěźÁĒüŚĎĹŚĎ®śúüŚõĘťėüÁöĄšļčŚģěšłäÁöĄŚąÜŚłÉŚľŹŤģ°Áģóś°Üśě∂„ÄāSpark3.0
śúÄŚŹóśúüŚĺÖÁöĄÁČĻśÄßšĻ蚳ĜėĮśĖįÁöĄŤá™ťÄāŚļĒśü•ŤĮĘśČߍ°Ćś°Üśě∂(Adaptive Query ExecutionÔľĆAQE)ԾƍĮ•ś°Üśě∂Ťß£ŚÜ≥šļÜŤģłŚ§ö Spark SQL Ś∑•šĹúŤīüŤĹĹťĀጹįÁöĄťóģťĘė„ÄāAQE Śú®2018ŚĻīŚąĚÁĒĪŤčĪÁČĻŚįĒŚíĆÁôĺŚļ¶ÁĽĄśąźÁöĄŚõĘťėüśúÄśó©ŚģěÁéį„ÄāAQE śúÄŚąĚśėĮŚú® Spark 2.4 šł≠ŚľēŚÖ•ÁöĄÔľĆ Spark 3.0 ŚĀö__ w397090770 __
2ŚĎ®ŚČć (05-23) __ 119‚ĄÉ __ 0ŤĮĄŤģļ__1ŚĖúś¨Ę
Spark__
APACHE SPARK 3.1 šł≠ STRUCTURED STREAMING śĖĻťĚĘÁöĄśĒĻŤŅõApache Spark 3.1.x
ÁČąśú¨ŚŹĎŚłÉŚąįÁéįŚú®Ś∑≤ÁĽŹŤŅášļÜšł§šł™Ś§öśúąšļÜԾƍŅôšł™ÁČąśú¨ÁĽßÁĽ≠šŅĚśĆĀšĹŅŚĺó Spark śõīŚŅęԾƜõīŚģĻśėďŚíĆśõīśôļŤÉĹÁöĄÁõģś†áÔľĆSpark 3.1 ÁöĄšłĽŤ¶ĀÁõģś†áŚ¶āšłčÔľöśŹźŚćášļÜ Python ÁöĄŚŹĮÁĒ®śÄßÔľõŚä†ŚľļšļÜ ANSI SQL ŚÖľŚģĻśÄßÔľõŚä†ŚľļšļÜśü•ŤĮĘšľėŚĆĖÔľõShuffle hash join śÄߍÉĹśŹźŚćáÔľõHistory Server śĒĮśĆĀ structured streamingśõīŚ§öŤĮ¶śÉÖŤĮ∑ŚŹāŤßĀŤŅôťáĆ„ÄāŚú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎšĽ¨śÄĽÁĽďšļÜ3.1ÁČąśú¨šł≠__ w397090770 __
3ŚĎ®ŚČć (05-16) __ 132‚ĄÉ __ 0ŤĮĄŤģļ__2ŚĖúś¨Ę
ŚÖ∂šĽĖ__
šĹŅÁĒ® FFMPEG śČĻťáŹŚźąŚĻ∂ŤßÜťĘĎFFmpeg
śėĮšłÄŚ•óŚŹĮšĽ•ÁĒ®śĚ•ŤģįŚĹē„ÄĀŤĹ¨śćĘśēįŚ≠óťü≥ťĘĎ„ÄĀŤßÜťĘĎԾƌĻ∂ŤÉĹŚįÜŚÖ∂ŤĹ¨ŚĆĖšłļśĶĀÁöĄŚľÄśļźŤģ°ÁģóśúļÁ®čŚļŹÔľĆťááÁĒ®LGPL śąĖ GPL
ŤģłŚŹĮŤĮĀ„ÄāŚģÉśŹźšĺõšļÜŚĹēŚą∂„ÄĀŤĹ¨śćĘšĽ•ŚŹäśĶĀŚĆĖťü≥ŤßÜťĘĎÁöĄŚģĆśēīŤß£ŚÜ≥śĖĻś°ą„ÄāŚģÉŚĆÖŚźęšļÜťĚ쌳łŚÖąŤŅõÁöĄťü≥ťĘĎ/ŤßÜťĘĎÁľĖŤß£Á†ĀŚļď libavcodecԾƚłļšļÜšŅĚŤĮĀťęėŚŹĮÁ߼ś§ćśÄߌíĆÁľĖŤß£Á†ĀŤī®ťáŹÔľĆlibavcodecťáƌ幌§ö code
ťÉĹśėĮšĽéŚ§īŚľÄŚŹĎÁöĄ„ÄāŚ¶āśěúśÉ≥ŚŹäśó∂šļÜŤß£Spark„ÄĀHadoopśąĖŤÄÖHBaseÁõł__ w397090770 __
1šł™śúąŚČć (04-30) __ 15‚ĄÉ __ 0ŤĮĄŤģļ__2ŚĖúś¨Ę
MongoDB__
MONGODB Śú®śü•ŤĮĘšł≠Śą©ÁĒ® $EXPR śĚ•ŚģěÁéįŤĀöŚźąŤ°®Ťĺĺ With MongoDB 3.6 the query language gains a new level of expressivity: you can now make use of aggregation expressions in a query using the $expr operator. This feature allows you to take full advantage of all expression operators within all queries, much of which previously had to be done within application logic or was restricted to the aggregation pipeline. $expr offers better performance than the $where operator, which while stilla
__ w397090770 __
1šł™śúąŚČć (04-27) __ 24‚ĄÉ __ 0ŤĮĄŤģļ__0ŚĖúś¨Ę
Kafka__
śĮŹšł™ APACHE KAFKA ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļčApache Kafka
śėĮšłÄšł™ŚľÄśļźśĶĀŚ§ĄÁźÜŚĻ≥ŚŹįԾƌ¶āšĽäśúČŤ∂ÖŤŅá30ÔľÖÁöĄŤīĘŚĮĆ500ŚľļšľĀšłöšĹŅÁĒ®ŤĮ•ŚĻ≥ŚŹį„ÄāKafka śúȌ幌§öÁČĻśÄßšĹŅŚÖ∂śąźšłļšļ蚼∂śĶĀŚĻ≥ŚŹįÔľąevent streaming platformÔľČÁöĄšļčŚģěšłäÁöĄś†áŚáÜ„ÄāŚú®ŤŅôÁĮáŚćöśĖášł≠ԾƜąĎŚįÜšĽčÁĽćśĮŹšł™ Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄšļĒšĽ∂šļčԾƍŅôś†∑Śú®šĹŅÁĒ® Kafka ŚįĪŚŹĮšĽ•ťĀŅŚÖćŚĺąŚ§öťóģťĘė„ÄāTip #1 ÁźÜŤß£ś∂ąśĀĮšľ†ťÄíŚíĆśĆĀšĻÖśÄßšŅĚŤĮĀŚĮĻšļéśēįśćģśĆĀšĻÖśÄßÔľądatadurabilityÔľČÔľĆ
__ w397090770 __
2šł™śúąŚČć (04-18) __ 358‚ĄÉ __ 0ŤĮĄŤģļ__0ŚĖúś¨Ę
Apache Iceberg__
APACHE ICEBERG Śú®ÁĹĎśėďšļĎťü≥šĻźÁöĄŚģěŤ∑Ķiceberg
ŤĮ¶ÁĽÜŤģĺŤģ°Apache iceberg śėĮNetflixŚľÄśļźÁöĄŚÖ®śĖįÁöĄŚ≠ėŚā®ś†ľŚľŹÔľĆśąĎšĽ¨Ś∑≤ÁĽŹśúČšļÜparquet„ÄĀorc„ÄĀarvoÁ≠ČťĚ쌳łšľėÁßÄÁöĄŚ≠ėŚā®ś†ľŚľŹšĽ•ŚźéÔľĆNetfixšłļšĽÄšĻąŤŅėŤ¶ĀŤģĺŤģ°ŚáļicebergŚĎĘÔľüŚíĆparquet„ÄĀorcÁ≠ČśĖᚼ∂ś†ľŚľŹšłćŚźĆÔľĆ icebergŚú®šłöÁēĆŤĘęÁßįšĻčšłļTable ForamtÔľĆparquet„ÄĀorc„ÄĀavroÁ≠ČśĖᚼ∂Á≠Čś†ľŚľŹŚłģŚä©śąĎšĽ¨ťęėśēąÁöĄšŅģśĒĻ„ÄĀŤĮĽŚŹĖŚćēšł™śĖᚼ∂ÔľõŚźĆś†∑Table ForamtŚłģŚä©śąĎšĽ¨ťęėśēąÁöĄšŅģśĒĻŚíĆŤĮĽŚŹĖšłÄÁĪĽśĖᚼ∂__ w397090770 __
2šł™śúąŚČć (04-15) __ 400‚ĄÉ __ 0ŤĮĄŤģļ__3ŚĖúś¨Ę
*
* 1
* 2
* 3
* 4
* 5
* 6
* ...
* 124
* šłčšłÄť°Ķ
* ŚÖĪ 124 ť°Ķ
__ __
__
ŤģĘťėÖŚŹ∑"iteblog_hadoop"____ __
ŚĺģšŅ°šļ§śĶĀ
ŤŅĎśúüśĖáÁę
* Presto Śä®śÄĀŤŅ᜼§Ôľądynamic filteringԾȌéüÁźÜšłéŚļĒÁĒ® * Delta Lake 1.0.0 ŚŹĎŚłÉԾƌ§öť°ĻśĖįÁČĻśÄßťáćÁ£ÖŚŹĎŚłÉ * Delta Lake: The Definitive Guide ťĘĄŤßąÁČąšłčŤĹĹ * Data Lakehouse ÁöĄśľĒŚŹė * Apache Spark 3.0 śėĮŚ¶āšĹēśŹźťęė SQL Ś∑•šĹúŤīüŤĹĹÁöĄśÄߍÉĹ * Apache Spark 3.1 šł≠ Structured Streaming śĖĻťĚĘÁöĄśĒĻŤŅõ * šĹŅÁĒ® ffmpeg śČĻťáŹŚźąŚĻ∂ŤßÜťĘĎ * MongoDB Śú®śü•ŤĮĘšł≠Śą©ÁĒ® $expr śĚ•ŚģěÁéįŤĀöŚźąŤ°®Ťĺĺ * śĮŹšł™ Apache Kafka ŚľÄŚŹĎŤÄÖťÉĹŚļĒŤĮ•Áü•ťĀďÁöĄ5šĽ∂šļč * Apache Iceberg Śú®ÁĹĎśėďšļĎťü≥šĻźÁöĄŚģěŤ∑Ķ * Apache Hudi 0.8.0 ÁČąśú¨ŚŹĎŚłÉÔľĆFlink ťõÜśąźśúČťá挧ߜŹźŚćᚼ•ŚŹäśĒĮśĆĀŚĻ∂Ť°ĆŚÜô * Ść≥ŚįÜŚŹĎŚłÉÁöĄ Apache Kafka 2.8 ŚįÜšłćťúÄŤ¶ĀšĺĚŤĶĖ ZookeeperԾƌćēťõÜÁ姜ĒĮśĆĀśēįÁôĺšłášł™ŚąÜŚĆļ* Apache
DolphinSchedulerÔľöŚõĹšļļšłĽŚĮľÁöĄŚąÜŚłÉŚľŹŚ∑•šĹúśĶĀŤįÉŚļ¶ŚĻ≥ŚŹįś≠£ŚľŹśąźšłļApache ť°∂Áļßť°ĻÁõģ
* ŚĒĮŚďĀšľö Apache Spark 3.0 ŚćáÁļßšĻčŤ∑Į * ClickHouse Śú®Śģěśó∂ŚúļśôĮÁöĄŚļĒÁĒ®ŚíĆšľėŚĆĖśúÄśĖįŤĮĄŤģļ
*
_w397090770_¬†¬†1ŚĎ®ŚČć (05-27)ŤĮīÔľöÁúčšłčŤŅôšł™śĖáś°£Ť°ĆšłćŤ°Ć https://docs.qubole.com/en/lat*
_AXL_¬†¬†1ŚĎ®ŚČć (05-26)ŤĮīÔľöŚ§ßšĹ¨ÔľĆťóģšł™ťóģťĘėÔľĆspark sqlŚŹĮšĽ•šĹŅÁĒ®rangerťČīśĚÉŚźó*
_AXL_¬†¬†2ŚĎ®ŚČć
(05-24)ŤĮīÔľörangerśėĮšłćśėĮšłćŚÖľŚģĻspark2.4.xԾƚłļšĽÄšĻąšľöśä•NoSuchMethod*
_w397090770_¬†¬†2ŚĎ®ŚČć (05-24)ŤĮīÔľöŚ¶āśěúšĹ†śúČŚ§öÁĽĄšĽ∂ŚÖĪÁĒ®ŚÖÉśēįśćģԾƌĽļŤģģÁĒ® Apache Ranger„ÄāŤŅôšł™ŚŹĮšĽ•ŚéĽŚŹāŤÄÉšłÄšłč*
_w397090770_¬†¬†2ŚĎ®ŚČć (05-24)ŤĮīÔľöŤŅôšł™šłćŤ°ĆÁöĄÔľĆÁĽôÁöĄśé•ŚŹ£ŚŹ™ŤÉĹśé•śĒ∂ÁĒ®śą∑ŚźćŚíĆŚĮÜÁ†Ā„ÄāŚļďÁļß„ÄĀŤ°®Áļß„ÄĀŤ°ĆÁļߍŅôšł™ŚŹĮšĽ•Áúčšłčhive
śõīŚ§ö ś†áÁ≠ĺ
Spark (417) Hadoop (153)ŤĶĄśĖôŚąÜšļę (116)
śĶ∑ťáŹśēįśćģŚ§ĄÁźÜ
(87) Kafka
(86) Hive (76)
Flink (65)
Java (58)
ÁĒĶŚ≠źšĻ¶ (56)
HiveÁöĄťā£šļõšļč (52)HBase (50)
ÁĹĎÁęôŚĽļŤģĺ (42)
ElasticSearch
(38) Spark meetup
(36) Spark 3.0
(34) Spark 2.0 (31)
Scala (30)
Linux (27)
Google (27)
ŚÖ¨šľóŚŹ∑ŤĹ¨ŤĹĹśĖáÁę(27)
śĖáÁꆌĹíś°£
* 2021ŚĻīŚÖ≠śúą
(1)
* 2021ŚĻīšļĒśúą
(5)
* 2021ŚĻīŚõõśúą
(8)
* 2021ŚĻīšłČśúą
(3)
* 2021ŚĻīšļĆśúą
(6)
* 2021ŚĻīšłÄśúą
(10)
* 2020ŚĻīŚćĀšļĆśúą
(11)
* 2020ŚĻīŚćĀšłÄśúą
(10)
* 2020ŚĻīŚćĀśúą
(11)
* 2020ŚĻīšĻĚśúą
(12)
* 2020ŚĻīŚÖęśúą
(9)
* 2020ŚĻīšłÉśúą
(7)
* 2020ŚĻīŚÖ≠śúą
(11)
* 2020ŚĻīšļĒśúą
(13)
* 2020ŚĻīŚõõśúą
(6)
* 2020ŚĻīšłČśúą
(6)
* 2020ŚĻīšļĆśúą
(11)
* 2020ŚĻīšłÄśúą
(8)
* 2019ŚĻīŚćĀšļĆśúą
(8)
* 2019ŚĻīŚćĀšłÄśúą
(8)
* 2019ŚĻīŚćĀśúą
(6)
* 2019ŚĻīšĻĚśúą
(13)
* 2019ŚĻīŚÖęśúą
(6)
* 2019ŚĻīšłÉśúą
(4)
* 2019ŚĻīŚÖ≠śúą
(8)
* 2019ŚĻīšļĒśúą
(6)
* 2019ŚĻīŚõõśúą
(13)
* 2019ŚĻīšłČśúą
(5)
* 2019ŚĻīšļĆśúą
(9)
* 2019ŚĻīšłÄśúą
(12)
* 2018ŚĻīŚćĀšļĆśúą
(8)
* 2018ŚĻīŚćĀšłÄśúą
(11)
* 2018ŚĻīŚćĀśúą
(6)
* 2018ŚĻīšĻĚśúą
(5)
* 2018ŚĻīŚÖęśúą
(12)
* 2018ŚĻīšłÉśúą
(11)
* 2018ŚĻīŚÖ≠śúą
(8)
* 2018ŚĻīšļĒśúą
(10)
* 2018ŚĻīŚõõśúą
(3)
* 2018ŚĻīšłČśúą
(4)
* 2018ŚĻīšļĆśúą
(3)
* 2018ŚĻīšłÄśúą
(15)
* 2017ŚĻīŚćĀšļĆśúą
(8)
* 2017ŚĻīŚćĀšłÄśúą
(6)
* 2017ŚĻīŚćĀśúą
(5)
* 2017ŚĻīšĻĚśúą
(8)
* 2017ŚĻīŚÖęśúą
(17)
* 2017ŚĻīšłÉśúą
(15)
* 2017ŚĻīŚÖ≠śúą
(13)
* 2017ŚĻīšļĒśúą
(9)
* 2017ŚĻīŚõõśúą
(9)
* 2017ŚĻīšłČśúą
(19)
* 2017ŚĻīšļĆśúą
(36)
* 2017ŚĻīšłÄśúą
(13)
* 2016ŚĻīŚćĀšļĆśúą
(16)
* 2016ŚĻīŚćĀšłÄśúą
(14)
* 2016ŚĻīŚćĀśúą
(17)
* 2016ŚĻīšĻĚśúą
(13)
* 2016ŚĻīŚÖęśúą
(38)
* 2016ŚĻīšłÉśúą
(20)
* 2016ŚĻīŚÖ≠śúą
(12)
* 2016ŚĻīšļĒśúą
(21)
* 2016ŚĻīŚõõśúą
(26)
* 2016ŚĻīšłČśúą
(25)
* 2016ŚĻīšļĆśúą
(11)
* 2016ŚĻīšłÄśúą
(11)
* 2015ŚĻīŚćĀšļĆśúą
(20)
* 2015ŚĻīŚćĀšłÄśúą
(14)
* 2015ŚĻīŚćĀśúą
(5)
* 2015ŚĻīšĻĚśúą
(8)
* 2015ŚĻīŚÖęśúą
(40)
* 2015ŚĻīšłÉśúą
(13)
* 2015ŚĻīŚÖ≠śúą
(16)
* 2015ŚĻīšļĒśúą
(34)
* 2015ŚĻīŚõõśúą
(27)
* 2015ŚĻīšłČśúą
(23)
* 2015ŚĻīšļĆśúą
(10)
* 2015ŚĻīšłÄśúą
(12)
* 2014ŚĻīŚćĀšļĆśúą
(17)
* 2014ŚĻīŚćĀšłÄśúą
(15)
* 2014ŚĻīŚćĀśúą
(19)
* 2014ŚĻīšĻĚśúą
(20)
* 2014ŚĻīŚÖęśúą
(9)
* 2014ŚĻīšłÉśúą
(9)
* 2014ŚĻīŚÖ≠śúą
(10)
* 2014ŚĻīšļĒśúą
(5)
* 2014ŚĻīŚõõśúą
(13)
* 2014ŚĻīšłČśúą
(15)
* 2014ŚĻīšļĆśúą
(11)
* 2014ŚĻīšłÄśúą
(17)
* 2013ŚĻīŚćĀšļĆśúą
(10)
* 2013ŚĻīŚćĀšłÄśúą
(11)
* 2013ŚĻīŚćĀśúą
(12)
* 2013ŚĻīšĻĚśúą
(17)
* 2013ŚĻīŚÖęśúą
(3)
* 2013ŚĻīšłÉśúą
(13)
* 2013ŚĻīŚÖ≠śúą
(1)
* 2013ŚĻīšļĒśúą
(7)
* 2013ŚĻīŚõõśúą
(48)
* 2013ŚĻīšłČśúą
(11)
ÁČąśĚÉśČÄśúČԾƚŅĚÁēôšłÄŚąáśĚÉŚą© ¬∑ŚüļšļéWordPressśěĄŚĽļ ¬© 2013-2019 ¬∑ ŚĻŅŚĎ䌟ąšĹú . ÁĹĎÁęôŚúįŚõĺ ¬∑śČÄśúČśĖáÁę
śú¨šłĽťĘėŚüļšļ霨≤śÄĚŚćöŚģĘšłĽťĘėšŅģśĒĻ šļ¨ICPŚ§á14057018ŚŹ∑__
Details
1